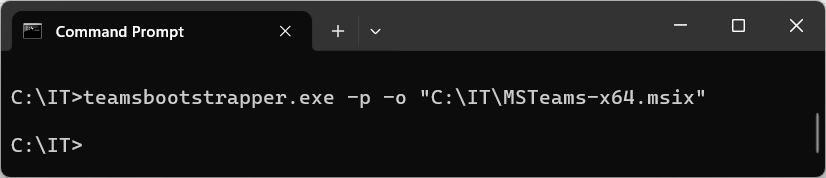Every organization is looking for ways to equip their mobile workforce, whether remote employees, travelling sales staff/representatives, or just providing more ways employees can work efficiently. Today I want to talk about Microsoft Teams Phone and VDI – a match made in the Cloud.
I’m one of those people who travel frequently and rely not only on having a reliable working environment, but also having access to telecommunications.
Running Teams Phone on VDI is a clear win in these regards!
VDI and VoIP, a common struggle
As most of you know, VDI and VoIP applications can be a major struggle with 3rd party applications not providing audio optimizations for environments that use VDI. This commonly results in in sluggish, jolty, delayed, and/or poor audio quality, in addition to audio processing in your VDI environment which uses resources on your VDI cluster.
For years, the most common applications including Microsoft Teams, Zoom, and even Skype for Business provided VDI optimizations to allow high quality (optimized) audio processing, resulting in almost perfect video/audio telecommunications via VDI sessions, when implemented properly.
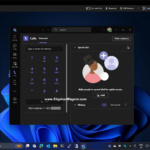
Teams Phone running on a VMware Horizon VDI Session
I was tired of using a 3rd party VoIP app, and wanted a more seamless experience, so I migrated over to Teams Phone for my organization, and I’m using it on VDI with VMware Horizon.
Microsoft Teams Phone
While I’ve heard a lot about Teams phone, Microsoft’s Phone System, and PSTN capabilities, I’ve only ever seen it deployed once in a client’s production environment. This put it on my list of curiosities to investigate in the future a few years back.
This past week I decided to migrate over to Microsoft Teams Phone for my organizations telephony and PSTN connectivity requirements. Not only did this eliminate my VoIP app on my desktops and laptops, but it also removed the requirement for a problematic VoIP client on my smartphone.
Teams Phone Benefits
Single app for team collaboration and VoIP
Single phone number (eliminates multiple extensions for multiple computers and devices)
Microsoft Phone System provides PBX capabilities
Cloud Based – No on-premise infrastructure required (except device & internet for client app)
I regularly use Microsoft Teams on all my desktops, laptops, and VDI sessions, along with my mobile phone, so the built-in capabilities for VoIP services, in an already fairly reliable app was a win-win!
I’ll go in to further detail on Teams Phone in a future blog post.
Teams Phone on VDI
Microsoft Teams already has VDI optimizations for video and audio in the original client and the new client. This provides an amazing high quality experience for users, while also offloading audio and video processing from your VDI environment to Microsoft Teams (handled by the endpoints and Microsoft’s servers).
When implementing Teams Phone on VDI, you take advantage of these capabilities providing an optimized and enhanced audio session for voice calls to the PSTN network.
This means you can have Teams running on a number of devices including your desktop, laptop, smartphone, VDI session, and have a single PSTN phone number that you can make and receive calls from, seamlessly.
Pretty cool, hey?
The Final Result
In my example, the final result will:
Reduce my corporate telephony costs by 50%
Eliminate the requirement for an on-prem PBX system
Remove the need for a 3rd party VoIP app on my workstations and mobile phone
Provide a higher quality end-user experience
Utilize existing VDI audio optimizations for a better experience
In this guide we will deploy and install the new Microsoft Teams for VDI (Virtual Desktop Infrastructure) client, and enable Microsoft Teams Media Optimization on Omnissa Horizon (formerly VMware Horizon).
This guide replaces and supersedes my old guide “Microsoft (Classic) Teams VDI Optimization for VMware Horizon” which covered the old Classic Teams client and VDI optimizations. The new Microsoft Teams app requires the same special considerations on VDI, and requires special installation instructions to function Omnissa Horizon and other VDI environments.
You can run the old and new Teams applications side by side in your environment as you transition users.
Switch between New Teams and old Teams on VDI
Let’s cover what the new Microsoft Teams app is about, and how to install it in your VDI deployment.
New Microsoft Teams app VDI optimized with Toggle for new/old version
Ultimately, it’s way faster, and consumes way less memory. And fortunately for us, it supports media optimizations for VDI environments.
My close friend and colleague, mobile jon, did a fantastic in-depth Deep Dive into the New Microsoft Teams and it’s inner workings that I highly recommend reading.
Interestingly enough, it uses the same media optimization channels for VDI as the old client used, so enablement and/or migrating from the old version is very simple if you’re running Omnissa Horizon, Citrix, AVD, and/or Windows 365.
Install New Microsoft Teams for VDI
While installing the new Teams is fairly simple for non-VDI environment (by simply either enabling the new version in the Teams Admin portal, or using your application manager to deploy the installer), a special method is required to deploy on your VDI images, whether persistent or non-persistent.
Do not include and bundle the Microsoft Teams install with your Microsoft 365 (Office 365) deployment as these need to be installed separately.
Please Note: If you have deployed non-persistent VDI (Instant Clones), you’ll want to make sure you disable auto-updates, as these should be performed manually on the base image. For persistent VDI, you will want auto updates enabled. See below for more information on configurating auto-updates.
You will also need to enable Microsoft Teams Media Optimization for the VDI platform you are using (in my case and example, Omnissa Horizon).
New Teams client app uses the same VDI media optimization channels as the old teams (for Omnissa Horizon, Citrix, AVD, and W365)
If you have already enabled Media Optimization for Teams on VDI for the old version, you can simply install the client using the special bulk installer for all users as shown below, as the new client uses the existing media optimizations.
While it is recommended to uninstall the old client and install the new client, you can choose to run both versions side by side together, providing an option to your users as to which version they would like to use.
Enable Media Optimization for Microsoft Teams on VDI
If you haven’t previously for the old client, you’ll need to enable the Teams Media Optimizations for VDI for your VDI platform.
For Omnissa Horizon, we’ll create a GPO and set the “Enable HTML5 Features” and “Enable Media Optimization for Microsoft Teams”, to “Enabled”. If you have done this for the old Teams app, you can skip this.
Computer Configuration -> Policies -> Administrative Templates -> Omnissa View Agent Configuration -> Omnissa HTML5 Features -> Omnissa WebRTC Redirection Features -> Enable Media Optimization for Microsoft Teams
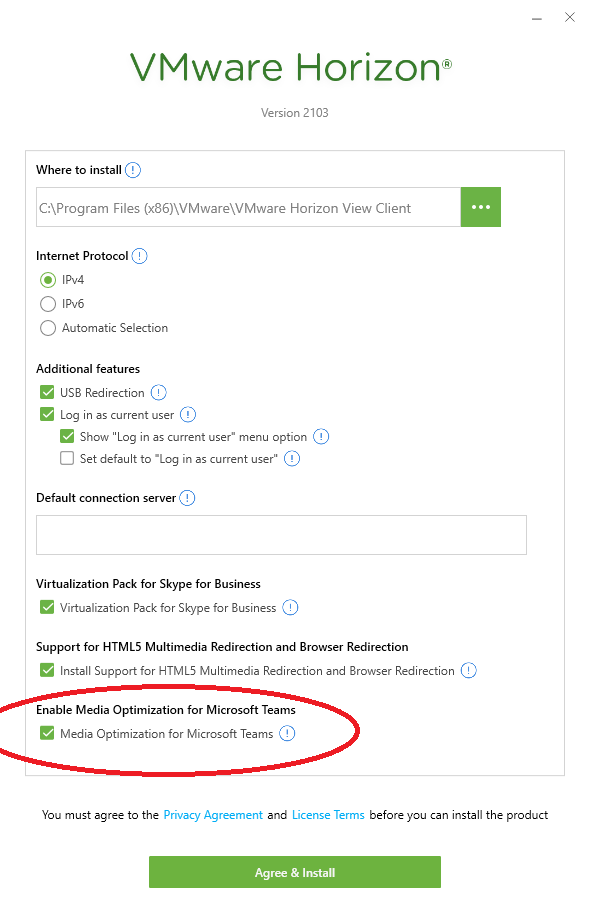
When installing the Omnissa Horizon client on Windows computers, you’ll need to make sure you check and enable the “Media Optimization for Microsoft Teams” option on the installer if prompted. Your install may automatically include Teams Optimization and not prompt.
Omnissa Horizon Client Install with Media Optimization for Microsoft Teams
If you are using a thin client or zero client, you’ll need to make sure you have the required firmware version installed, and any applicable vendor plugins installed and/or configurables enabled.
Install New Microsoft Teams client on VDI
At this time, we will now install the new Teams app on to both non-persistent images, and persistent VDI VM guests. This method performs a live download and provisions as Administrator. If running this un-elevated, an elevation prompt will appear:
New Teams admin provisioned offline install for VDI
For the offline installation, you’ll need to download the appropriate MSI-X file in additional to the bootstrapper above. See below for download links:
For non-persistent environments, you’ll want to disable the auto update feature and install updates manually on your base image.
To disable auto-updates for the new Teams client, configure the registry key below on your base image:
HKEY_LOCAL_MACHINE\SOFTWARE\Microsoft\Teams
Create a DWORD value called “disableAutoUpdate”, and set to value of “1”.
New Teams app disappears after Optimization with OSOT
If you are using the Omnissa Operating System Optimization Tool (OSOT), you may notice that after installing New Teams in your base or golden image, that it disappears when publishing and pushing the image to your desktop pool.
The New Teams application is a Windows Store app, and organizations commonly choose to remove all Windows Store apps inside the golden image using the OSOT tool when optimizing the image. Doing this will remove New Teams from your image.
To workaround this issue, you’ll need to choose “Keep all Windows Store Applications” in the OSOT common options, which won’t remove Teams.
Using New Microsoft Teams with FSLogix Profile Containers
When using the new Teams client with FSLogix Profile Containers on non-persistent VDI, you must upgrade to FSLogix version 2.9.8716.30241 to support the new teams client.
Confirm New Microsoft Teams VDI Optimization is working
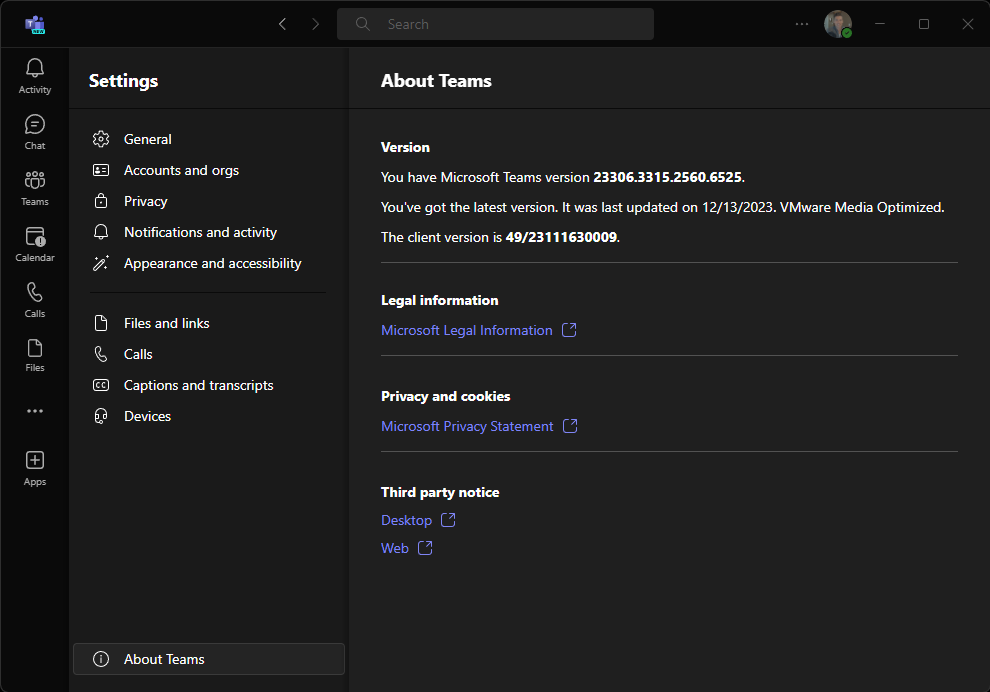
To confirm that VDI Optimization is working on New Teams, open New Teams, click the “…” in the top right next to your user icon, click “Settings”, then click on “About Teams” on the far bottom of the Settings menu.
New Teams showing “Omnissa Media Optimized”
You’ll notice “Omnissa Media Optimized” which indicates VDI Optimization for Omnissa Horizon is functioning. The text will reflect for other platforms as well.
Uninstall New Microsoft Teams on VDI
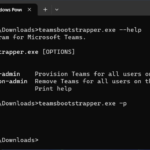
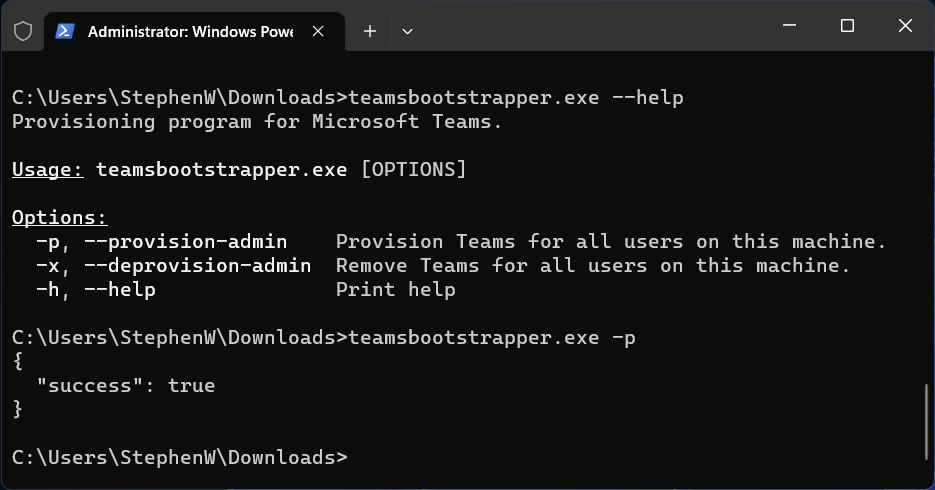
The Teams Boot Strap utility can also remove teams for all users on this machine as well by using the “-x” flag. Please see below for all the options for “teamsbootstrapper.exe”:
C:\Users\Administrator.DOMAIN\Downloads>teamsbootstrapper.exe --help
Provisioning program for Microsoft Teams.
Usage: teamsbootstrapper.exe [OPTIONS]
Options:
-p, --provision-admin Provision Teams for all users on this machine.
-x, --deprovision-admin Remove Teams for all users on this machine.
-h, --help Print help
Install New Microsoft Teams on Omnissa App Volumes / Citrix App Layering
Previously, using the New Teams bootstrapper, it appeared that it evaded and didn’t work with App Packaging and App attaching technologies such as Omnissa App Volumes and Citrix Application layering, however following the instructions on KB97141 will work.
The New Teams bootstrapper downloads and installs an MSIX app package to the computer running the bootstrapper.
Conclusion
It’s great news that we finally have a better performing Microsoft Teams client that supports VDI optimizations. With new Teams support for VDI reaching GA, and with the extensive testing I’ve performed in my own environment, I’d highly recommend switching over at your convenience!
In May of 2023, NVIDIA released the NVIDIA GPU Manager for VMware vCenter. This appliance allows you to manage your NVIDIA vGPU Drivers for your VMware vSphere environment.
Since the release, I’ve had a chance to deploy it, test it, and use it, and want to share my findings.
In this post, I’ll cover the following (click to skip ahead):
The NVIDIA GPU Manager is an (OVA) appliance that you can deploy in your VMware vSphere infrastructure (using vCenter and ESXi) to act as a driver (and update) repository for vLCM (vSphere Lifecycle Manager).
In addition to acting as a repo for vLCM, it also installs a plugin on your vCenter that provides a GUI for browsing, selecting, and downloading NVIDIA vGPU host drivers to the local repo running on the appliance. These updates can then be deployed using LCM to your hosts.
In short, this allows you to easily select, download, and deploy specific NVIDIA vGPU drivers to your ESXi hosts using vLCM baselines or images, simplifying the entire process.
Supported vSphere Versions
The NVIDIA GPU Manager supports the following vSphere releases (vCenter and ESXi):
VMware vSphere 8.0 (and later)
VMware vSphere 7.0U2 (and later)
The NVIDIA GPU Manager supports vGPU driver releases 15.1 and later, including the new vGPU 16 release version.
How to deploy and configure the NVIDIA GPU Manager for VMware vCenter
To deploy the NVIDIA GPU Manager Appliance, we have to download an OVA (from NVIDIA’s website), then deploy and configure it.
See below for the step by step instructions:
Download the NVIDIA GPU Manager
Log on to the NVIDIA Application Hub, and navigate to the “NVIDIA Licensing Portal” (https://nvid.nvidia.com).
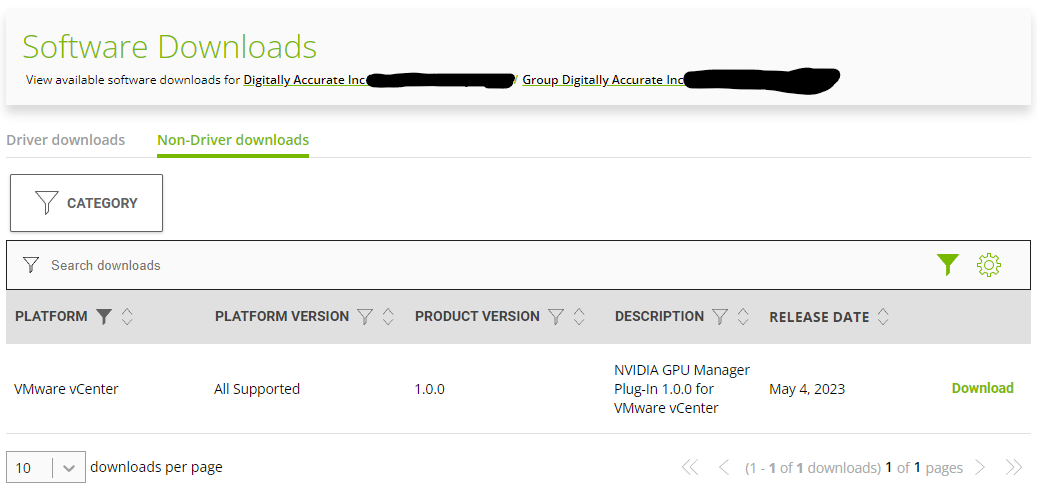
Navigate to “Software Downloads” and select “Non-Driver Downloads”
Change Filter to “VMware vCenter” (there is both VMware vSphere, and VMware vCenter, pay attention to select the correct).
To the right of “NVIDIA GPU Manager Plug-in 1.0.0 for VMware vCenter”, click “Download” (see below screenshot).
NVIDIA GPU Manager Download Page
After downloading the package and extracting, you should be left with the OVA, along with Release Notes, and the User Guide. I highly recommend reviewing the documentation at your leisure.
Deploy and Configure the NVIDIA GPU Manager
We will now deploy the NVIDIA GPU Manager OVA appliance:
Deploy the OVA to either a cluster with DRS, or a specific ESXi host. In vCenter either right click a cluster or host, and select “Deploy OVF Template”. Choose the GPU Manager OVA file, and continue with the wizard.
Configure Networking for the Appliance
You’ll need to assign an IP Address, and relevant networking information.
I always recommend creating DNS (forward and reverse entries) for the IP.
Finally, power on Appliance.
We must now create a role and service account that the GPU Manager will use to connect to the vCenter server.
While the vCenter Administrator account will work, I highly recommend creating a service account specifically for the GPU Manager that only has the required permissions that are necessary for it to function.
Log on to your vCenter Server
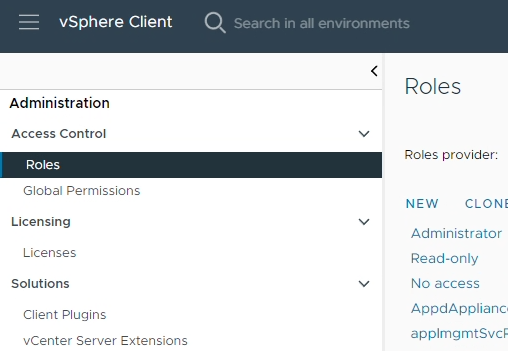
Click on the hamburger menu item on the top left, and open “Administration”.
Under “Access Control” select Roles.
Select New to create a new role. We can call it “NVIDIA Update Services”.
***PLEASE NOTE: The above permissions were provided in the documentation and did not work for me (resulted in an insufficient privileges error). To resolve this, I chose “Select All” for “VMware vSphere Lifecycle Manager”, which resolved the issue.***
Save the Role
On the left hand side, navigate to “Users and Groups” under “Single Sign On”
Change the domain to your local vSphere SSO domain (vsphere.local by default)
Create a new user account for the NVIDIA appliance, as an example you could use “nvidia-svc”, and choose a secure password.
Navigate to “Global Permissions” on the left hand side, and click “Add” to create a new permission.
Set the domain, and choose the new “nvidia-svc” service account we created, and set the role to “NVIDIA Update Services”, and check “Propagate to Children”.
You have now configured the service account.
Now, we will perform the initial configuration of the appliance. To configure the application, we must do the following:
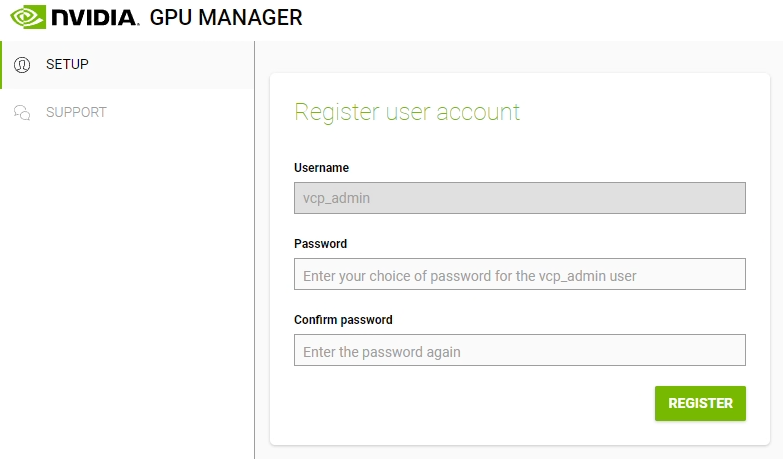
Access the appliance using your browser and the IP you configured above (or FQDN)
Create a new password for the administrative “vcp_admin” account. This account will be used to manage the appliance.
A secret key will be generated that will allow the password to be reset, if required. Save this key somewhere safe.
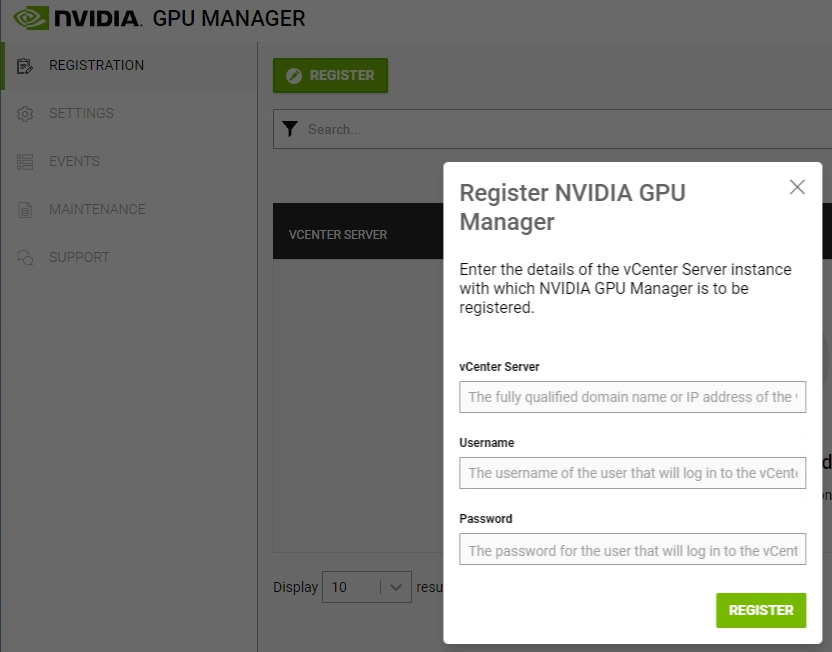
We must now register the appliance (and plugin) with our vCenter Server. Click on “REGISTER”.
Enter the FQDN or IP of your vCenter server, the NVIDIA Service account (“nvidia-svc” from example), and password.
Once the GPU Manager is registered with your vCenter server, the remainder of the configuration will be completed from the vCenter GPU.
The registration process will install the GPU Manager Plugin in to VMware vCenter
The registration process will also configure a repository in LCM (this repo is being hosted on the GPU manager appliance).
We must now configure an API key on the NVIDIA Licensing portal, to allow your GPU Manager to download updates on your behalf.
Open your browser and navigate to https://nvid.nvidia.com. Then select “NVIDIA LICENSING PORTAL”. Login using your credentials.
On the left hand side, select “API Keys”.
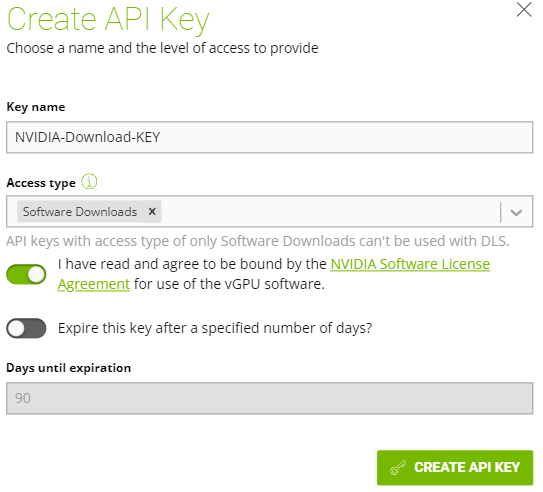
On the upper right hand, select “CREATE API KEY”.
Give the key a name, and for access type choose “Software Downloads”. I would recommend extending the key validation time, or disabling key expiration.
The key should now be created.
Click on “view api key”, and record the key. You’ll need to enter this in later in to the vCenter GPU Manager plugin.
And now we can finally log on to the vCenter interface, and perform the final configuration for the appliance.
Log on to the vCenter client, click on the hamburger menu, and select “NVIDIA GPU Manager”.
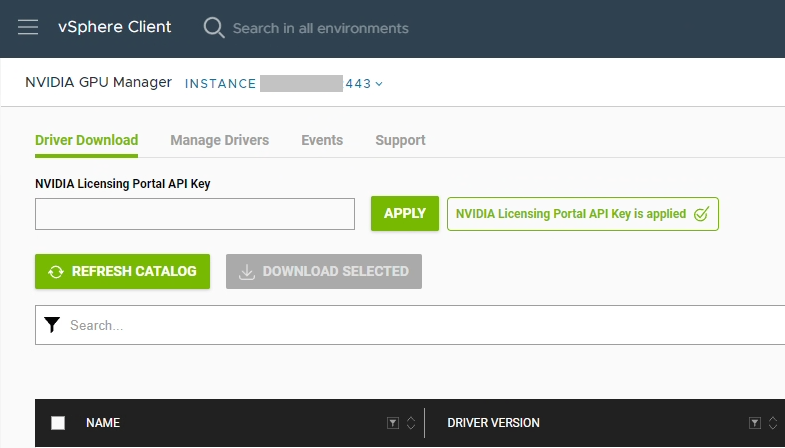
Enter the API key you created above in to the “NVIDIA Licensing Portal API Key” field, and select “Apply”.
The appliance should now be fully configured and activated.
Configuration is complete.
We have now fully deployed and completed the base configuration for the NVIDIA GPU Manager.
Using the NVIDIA GPU Manager to manage, update, and deploy vGPU drivers to ESXi hosts
In this section, I’ll be providing an overview of how to use the NVIDIA GPU Manager to manage, update, and deploy vGPU drivers to ESXi hosts. But first, lets go over the workflow…
The workflow is a simple one:
Using the vCenter client plugin, you choose the drivers you want to deploy. These get downloaded to the repo on the GPU Manager appliance, and are made available to Lifecycle Manager.
You then use Lifecycle Manager to deploy the vGPU Host Drivers to the applicable hosts, using baselines or images.
As you can see, there’s not much to it, despite all the configuration we had to do above. While it is very simple, it simplifies management quite a bit, especially if you’re using images with Lifecycle Manager.
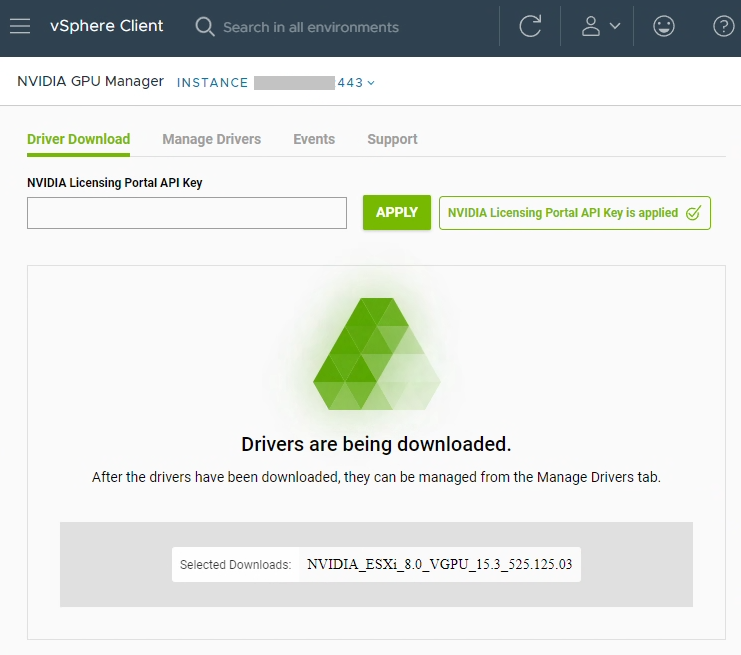
To choose and download the drivers, load up the plugin, use the filters to filter the list, and select your driver to download.
NVIDIA GPU Manager downloading vGPU Driver
As you can see in the example, I chose to download the vGPU 15.3 host driver. Once completed, it’ll be made available in the repo being hosted on the appliance.
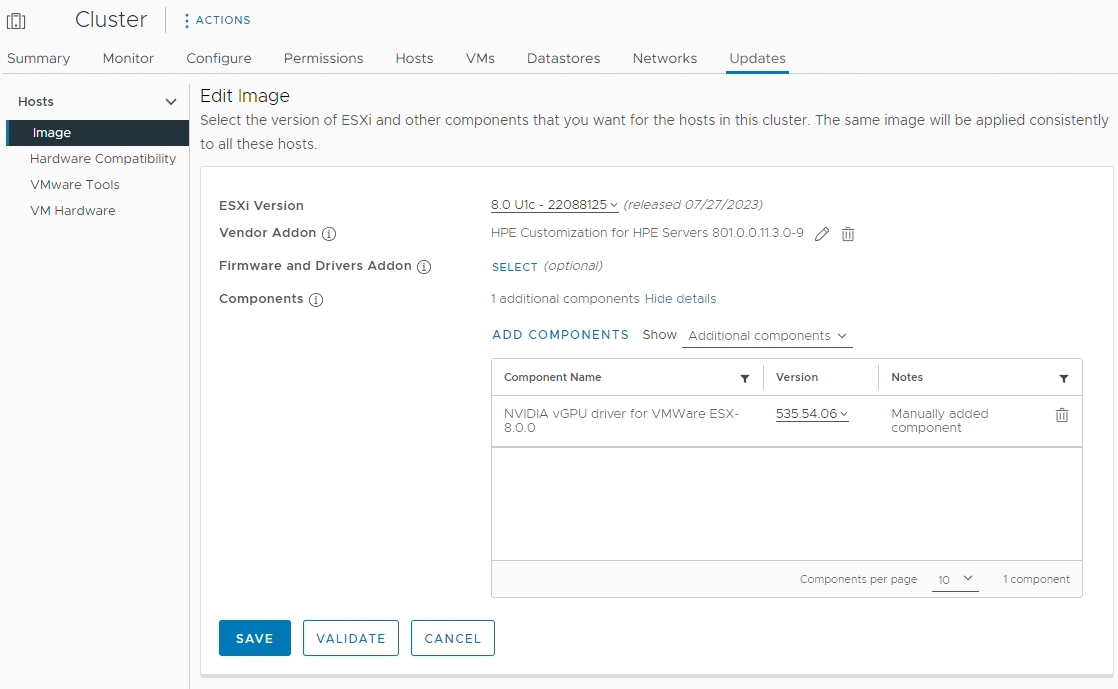
Once LCM has a changed to sync with the updated repos, the driver is then made available to be deployed. You can then deploy using baselines or host images.
LCM Image Update with NVIDIA vGPU Driver from NVIDIA GPU Manager
In the example above, I added the vGPU 16 (535.54.06) host driver to my clusters update image, which I will then remediate and deploy to all the hosts in that cluster. The vGPU driver was made available from the download using GPU Manager.
When it comes to virtualized workloads, one thing I commonly see overlooked in the design of the solution, is the placement of workloads. In this post, I want to cover VMware vSphere VM placement rules using the “VM/Host Rules” feature.
This is a feature that I commonly see overlooked and not configured, especially in smaller single cluster environments, however I’ve also seen this happen in very large scale environments as well.
Let’s cover the why, what, who, and how…
VM Workloads
While VMware vSphere does have a number of technologies built in for redundancy, load-balancing, and availability, as part of the larger solution we often find our workloads, specifically 3rd party platforms, with their own solutions that accomplish the same thing.
We need to identify which HA (High Availability) or redundancy solution to use, based on the application, service, and how it works.
For example, using VMware vSphere HA, or High Availability, if vCenter (and/or vCLS) detects a host goes offline, it can restart the workload on other online hosts. There is time associated with the detection and boot time, resulting in a loss of service during this period.
Third party solutions often have their own high availability or redundancy built in to the solution, such as Microsoft Active Directory. In this case with a standard configuration, at any time, any domain controller can respond to a clients request for resources. If one DC goes offline, other DCs can respond to the request resulting in no downtime.
Obviously, in the case of Active Directory Domain Controllers, you’d much prefer to have multiple DCs in your environment, instead of using one with vSphere HA.
Additionally, if you did have multiple domain controllers, you’d want to make sure they aren’t all placed on the same ESXi host. This is where we start to incorporate VM placement in to our solution.
VM Placement
When it comes to 3rd party solutions like mentioned above, we need to identify these workloads and factor them in to the design of the solution we are either implementing, maintaining, or improving.
Example of VM workloads used with VM Placement
A few examples of these workloads with their own load-balancing and availability technologies:
Microsoft Windows Active Directory Domain Controllers
Microsoft Windows Servers running DNS/DHCP Servers
Virtualized Active/Active or Active/Passive Firewall Appliances
VMware Horizon UAG (Unified Access Gateway) configured in HA mode
Other servers/services that have their own availability systems
As you can see, the applications all have their own special solution for availability, so we must insure the different “nodes” or “instances” are running on different ESXi hosts to avoid a host failure bringing down the entire solution.
Unless otherwise specified by the 3rd party vendor, I would recommend using VM/Host Rules in combination with vSphere DRS and HA.
Configuring VM Placement with VM/Host Rules
To configure these rules, follow the instructions below:
Log on to your VMware vCenter Server
Select a Cluster
Click on the “Configure” tab, and then “VM/Host Rules”
Here you can Add/Edit/Delete VM Host Rules
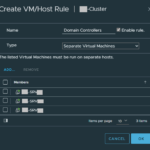
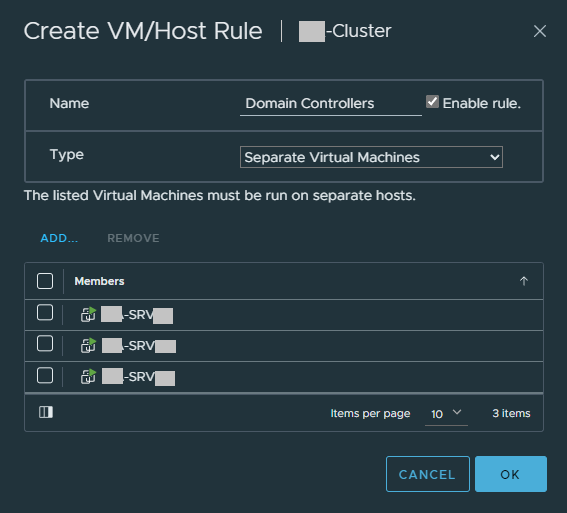
Click on “Add”, and give the rule a new name (Example: Domain Controllers)
For “Type”, select “Separate Virtual Machines”
Click “Add” and select your Domain Controllers and add them to the rule.
Domain Controller VM Placement VM Host Rule
After you click “OK”, the rule should now be saved, and DRS will make sure these VMs are now running on separate hosts.
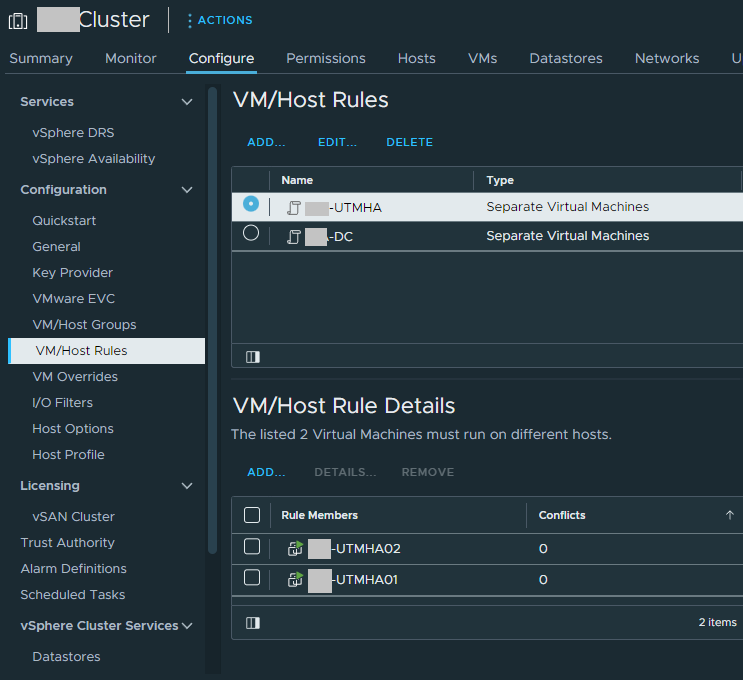
Below you can see another example of a configured system, separating 2 Active/Passive Firewall appliances.
VM/Host Rules for Firewall Appliances
As you can see, VM placement with VM/Host Rules is very easy to configure and deploy.
Additional Considerations
Note, if you implement these rules and do not have enough hosts to fullfill the requirements, the hosts may fail to be evacuated by DRS when placing in maintenance mode, or remediating with vLCM (Lifecycle Manager).
In this case, you’ll need to manually vMotion the VM’s to other hosts (to violate the rule) or shut some down.
A few months ago, you may have seen my post detailing my experience with ESXi 7.0 on HP Proliant DL360p Gen8 servers. I now have an update as I have successfully loaded ESXi 8.0 on HPE Proliant DL360p Gen8 servers, and want to share my experience.
It wasn’t as eventful as one would have expected, but I wanted to share what’s required, what works, and stability observations.
Please note, this is NOT supported and NOT recommended for production environments. Use the information at your own risk.
A special thank you goes out to William Lam and his post on Homelab considerations for vSphere 8, which provided me with the boot parameter required to allow legacy CPUs.
ESXi on the DL360p Gen8
With the release of vSphere 8.0 Update 1, and all the new features and functionality that come with the vSphere 8 release as a whole, I decided it was time to attempt to update my homelab.
In my setup, I have the following:
2 x HPE Proliant DL360p Gen8 Servers
Dual Intel Xeon E5-2660v2 Processors in each server
USB and/or SD for booting ESXi
No other internal storage
NVIDIA A2 vGPU (for use with VMware Horizon)
External SAN iSCSI Storage
Since I have 2 servers, I decided to do a fresh install using the generic installer, and then use the HPE addon to install all the HPE addons, drivers, and software. I would perform these steps on one server at a time, continuing to the next if all went well.
I went ahead and documented the configuration of my servers beforehand, and had already had upgraded my VMware vCenter vCSA appliance from 7U3 to 8U1. Note, that you should always upgrade your vCenter Server first, and then your ESXi hosts.
To my surprise the install went very smooth (after enabling legacy CPUs in the installer) on one of the hosts, and after a few days with no stability issues, I then proceeded and upgraded the 2nd host.
I’ve been running with 100% for 25+ days without any issues.
The process – Installing ESXi 8.0
I used the following steps to install VMware vSphere ESXi 8 on my HP Proliant Gen8 Server:
Download the Generic ESXi installer from VMware directly.
Boot server with Generic ESXi installer media (CD or ISO)
IMPORTANT: Press “Shift + o” (Shift key, and letter “o”) to interrupt the ESXi boot loader, and add “AllowLegacyCPU=true” to the kernel boot parameters.
Continue to install ESXi as normal.
You may see warnings about using a legacy CPU, you can ignore these.
Complete initial configuration of ESXi host
Mount NFS or iSCSI datastore.
Copy HPE Custom Addon for ESXi zip file to datastore.
Enable SSH on host (or use console).
Place host in to maintenance mode.
Run “esxcli software vib install -d /vmfs/volumes/datastore-name/folder-name/HPE-801.0.0.11.3.1.1-Jun2023-Addon-depot.zip” from the command line.
The install will run and complete successfully.
Restart your server as needed, you’ll now notice that not only were HPE drivers installed, but also agents like the Agentless management agent, and iLO integrations.
After that, everything was good to go… Here you can see version information from one of the ESXi hosts:
VMware ESXi version 8.0.1 Build 21813344 on HPE Proliant DL360p Gen8 Server
What works, and what doesn’t
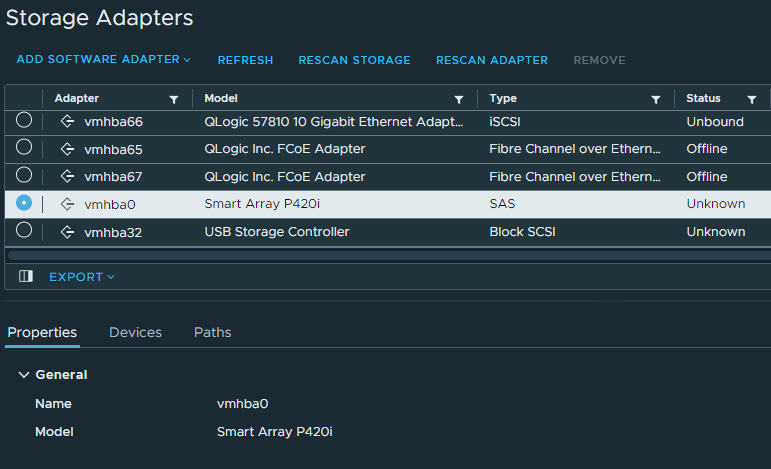
I was surprised to see that everything works, including the P420i embedded RAID controller. Please note that I am not using the RAID controller, so I have not performed extensive testing on it.
HPE P420i RAID Controller with VMware vSphere ESXi 8
All Hardware health information is present, and ESXi is functioning as one would expect if running a supported version on the platform.
Additional Information
Note that with vSphere 8, VMware is deprecating vLCM baselines. Your focus should be to update your ESXi instances using cluster image based update images. You can incorporate vendor add-ons and components to create a customized image for deployment.
This website uses cookies to improve your experience. We'll assume you're ok with this, but you can opt-out if you wish.
Do you accept the use of cookies and accept our privacy policy? AcceptRejectCookie and Privacy Policy
Privacy & Cookies Policy
Privacy Overview
This website uses cookies to improve your experience while you navigate through the website. Out of these cookies, the cookies that are categorized as necessary are stored on your browser as they are essential for the working of basic functionalities of the website. We also use third-party cookies that help us analyze and understand how you use this website. These cookies will be stored in your browser only with your consent. You also have the option to opt-out of these cookies. But opting out of some of these cookies may have an effect on your browsing experience.