One really cool feature that was released in VMware Horizon View 7.7 (and Horizon 8), is the ability to install the Horizon Agent on to a Physical PC or Physical Workstation and use the Blast Extreme protocol. It even supports 3D Acceleration via a GPU and the direct-connect plugin (so you don’t need to have/use a View Connection Server)!
Update July 20, 2022: With the release of Horizon 8 2206, you can now install the Horizon agent on Windows 10 Pro, and Edu editions. Previous versions of Horizon required Windows 10 Enterprise.
As a system admin, I see value in having some Physical PCs managed by the View connection server. Also, if you have the licensing, this will allow you to set this up as a remote access solution for your business and employees.
I’ll be detailing some information about doing this, what’s required, what works, and what doesn’t below…
The details…
From the “What’s new in Horizon 7.7” doc at https://blogs.vmware.com/euc/2018/12/whats-new-horizon-7-7.html
You can now use the Blast Extreme display protocol to access physical PCs and workstations. Some limitations apply.
Additional information from the “Horizon 7.7 Release Notes” at https://docs.vmware.com/en/VMware-Horizon-7/7.7/rn/horizon-77-view-release-notes.html
Physical PCs and workstations with Windows 10 1803 Enterprise or higher can be brokered through Horizon 7 via Blast Extreme protocol.
Requirements
So here’s what’s required to get going:
- Windows 10 Enterprise (for Horizon versions before Horizon 8 2206)
- Windows 10 Pro or Edu (for Horizon 8 2206 and later)
- Physical PC or Workstation
- VMware Horizon Licensing
- VMware Horizon 7.7 or higher (and Horizon 8) Connection Server
- VMware Horizon 7.7 or higher (and Horizon 8) Agent on Physical PC/Workstation
- Manual Desktop Pool (Manual is required for Physical PCs to be added)
What Works
- Blast Extreme
- 3D Acceleration (via GPU with drivers)
- 3D Acceleration with Consumer GPUs
- Multiple Displays
- Multiple GPUs
- VMware View Agent Direct-Connection Plug-In
What Doesn’t Work
- GPU Hardware h.264 encoding on consumer GPUs (h.264 encoding is still handled by the CPU)
- GPU Hardware h.264/h.265 offload may work in later versions (I still need to test this)
Thoughts
I’ve been really enjoying this feature. Not only have I moved my desktop in to my server room and started remoting in using Blast, but I can think of many use cases for this (machines shops, sharing software licenses, remote access, etc.).
I’ve had numerous discussions with customers of mine who also say they see tremendous value in this after I brought it to their attention. I’ll update this post later on once I hear back about how some of my customers have deployed it.
Update – March 14th 2020 – I’ve been using this on 3 different systems since I wrote this article and love this feature!
3D Acceleration
One thing that is really cool, is the fact that 3D acceleration is enabled and working if the computer has a GPU installed (along with drivers). And no, you don’t need a fancy enterprise GPU. In my setup I’m running a GeForce 550 GTX TI, and a GeForce 640.
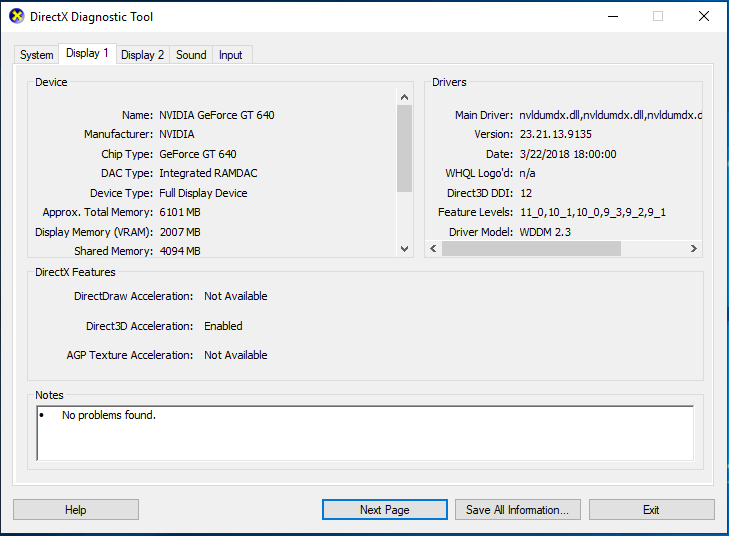
While 3D acceleration is working, I have to note that the h.264 encoding for the Blast Extreme session is still being handled by the CPU. So while you are getting some great 3D accelerated graphics, depending on your CPU and screen resolution, you may be noticing some choppiness. If you have a higher end CPU, you should be able to get some pretty high resolutions. I’m currently running 2 displays at 1920×1080 on an extremely old Core 2 Quad processor.
H.264 encoding
I spent some time trying to enable the hardware h.264 encoder on the GPUs. Even when using the “NvFBCEnable.exe” (located in C:\Program Files\VMware\VMware Blast\) application to enable hardware encoding, I still notice that the encoding is being done on the CPU. I’m REALLY hoping they change this in future releases.
Hacks?
Another concept that this opens the door for is consumer GPUs providing 3D acceleration without all the driver issues. Technically you could use the CPU settings (to hide the fact the VM is being virtualized), and then install the Horizon Agent as a physical PC (even though it’s being virtualized). This should allow you to use the GPU that you’re passing through, but you still won’t get h.264 encoding on the GPU. This should stop the pesky black screen issue that’s normally seen when using this work around.
Bugs
When upgrading to Horizon View 8 or higher, as part of the process to upgrade the agent on the physical machine, you may notice this functionality stops working. To resolve this, simply uninstall the agent and then re-install it.
Also, on a final note… I did find a bug where if any of the physical PCs are powered down or unavailable on the network, any logins from users entitled to that pool will time out and not work. When this issue occurs, a WoL (Wake on LAN) packet is sent to the desktop during login, and the login will freeze until the physical PC becomes available. This occurs during the login phase, and will happen even if you don’t plan on using that pool. More information can be found here:
https://www.stephenwagner.com/2019/03/19/vmware-horizon-view-stuck-authenticating-logging-in/
More Information
Since the date of this post, VMware Tech Zone released a useful post outlining details on Using Horizon to Access Physical Windows Machines. I highly recommend you check it out!