We all know that vMotion is awesome, but what is even more awesome? Optimizing VMware vMotion to make it redundant and faster!
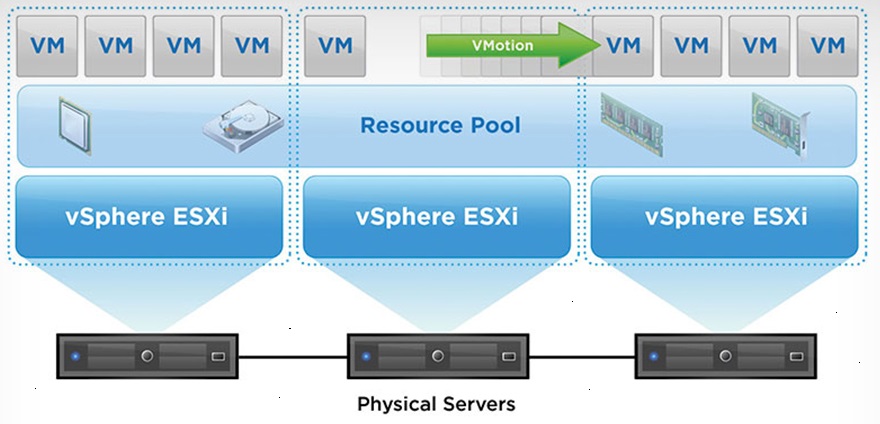
vMotion allows us to migrate live Virtual Machines from one ESXi host to another without any downtime. This allows us to perform physical maintenance on the ESXi hosts, update and restart the hosts, and also load balance VMs across the hosts. We can even take this a step further use DRS (Distributed Resource Scheduler) automation to intelligently load the hosts on VM boot and to dynamically load balance the VMs as they run.
VMware vMotion
In this post, I’m hoping to provide information on how to fully optimize and use vMotion to it’s full potential.
VMware vMotion
Most of you are probably running vMotion in your environment, whether it’s a homelab, dev environment, or production environment.
I typically see vMotion deployed on the existing data network in smaller environments, I see it deployed on it’s own network in larger environments, and in very highly configured environments I see it being used with the vMotion TCP stack.
While you can preform a vMotion with 1Gb networking, you certainly almost always want at least 10Gb networking for the vMotion network, to avoid any long running VMs. Typically most IT admins are happy with live migration vMotion’s in the seconds, and not the minutes.
VMware vMotion Optimization
So you might ask, if vMotion is working and you’re satisfied, what is there to optimize? There’s actually a few things, but first let’s talk about what we can improve on.
We’re aiming for improvements with:
Throughput/Speed
Faster vMotion
Faster Speed
Less Time
Migrate more VMs
Evacuate hosts faster
Enable more aggressive DRS
Migrate many VMs at once very quickly
Redundancy
Redundant vMotion Interfaces (NICs and Uplinks)
More Complex vMotion Configurations
vMotion over different subnets and VLANs
vMotion routed over Layer 3 networks
To achieve the above, we can focus on the following optimizations:
Enable Jumbo Frames
Saturation of NIC/Uplink for vMotion
Multi-NIC/Uplink vMotion
Use of the vMotion TCP Stack
Let’s get to it!
Enable Jumbo Frames
I can’t stress enough how important it is to use Jumbo Frames for specialized network traffic on high speed network links. I highly recommend you enable Jumbo Frames on your vMotion network.
Note, that you’ll need to have a physical switch and NICs that supports Jumbo frames.
In my own high throughput testing on a 10Gb link, without using Jumbo frames I was only able to achieve transfer speeds of ~6.7Gbps, whereas enabling Jumbo Frames allowed me to achieve speeds of ~9.8Gbps.
When enabling this inside of vSphere and/or ESXi, you’ll need to make sure you change and update the applicable vmk adapter, vSwitch/vDS switches, and port groups. Additionally as mentioned above you’ll need to enable it on your physical switches.
Saturation NIC/Uplink for vMotion
You may assume that once you configure a vMotion enabled NIC, that when performing migrations you will be able to fully saturate it. This is not necessarily the case!
When performing a vMotion, the vmk adapter is bound to a single thread (or CPU core). Depending on the power of your processor and the speed of the NIC, you may not actually be able to fully saturate a single 10Gb uplink.
In my own testing in my homelab, I needed to have a total of 2 VMK adapters to saturate a single 10Gb link.
If you’re running 40Gb or even 100Gb, you definitely want to look at adding multiple VMK adapters to your vMotion network to be able to fully saturate a single NIC or Uplink.
You can do this by simply configuring multiple VMK adapters per host with different IP addresses on the same subnet.
One important thing to mention is that if you have multiple physical NICs and Uplinks connected to your vMotion switch, this change will not help you utilize multiple physical interfaces (NICs/Uplinks). See “Multi-NIC/Uplink vMotion”.
Please note: As of VMware vSphere 7 Update 2, the above is not required as vMotion has been optimized to use multiple streams to fully saturate the interface. See VMware’s blog post “Faster vMotion Makes Balancing Workloads Invisible” for more information.
Multi-NIC/Uplink vMotion
Another situation is where we may want to utilize multiple NICs and Uplinks for vMotion. When implemented correctly, this can provide load balancing (additional throughput) as well as redundancy on the vMotion network.
If you were to simply add additional NIC interfaces as Uplinks to your vMotion network, this would add redundancy in the event of a failover but it wouldn’t actually result in increased speed or throughput as special configuration is required.
To take advantage of the additional bandwidth made available by additional Uplinks, we need to specially configure multiple portgroups on the switch (vSwitch or vDS Distributed Switch), and configure each portgroup to only use one of the Uplinks as the “Active Uplink” with the rest of the uplinks under “Standby Uplink”.
Example Configuration
vSwitch or vDS Switch
Portgroup 1
Active Uplink: Uplink 1
Standby Uplinks: Uplink 2, Uplink 3, Uplink 4
Portgroup 2
Active Uplink: Uplink 2
Standby Uplinks: Uplink 1, Uplink 3, Uplink 4
Portgroup 3
Active Uplink: Uplink 3
Standby Uplinks: Uplink 1, Uplink 2, Uplink 4
Portgroup 4
Active Uplink: Uplink 4
Standby Uplinks: Uplink 1, Uplink 2, Uplink 3
You would then place a single or multiple vmk adapters on each of the portgroups per host, which would result in essentially mapping the vmk(s) to the specific uplink. This will allow you to utilize multiple NICs for vMotion.
And remember, you may not be able to fully saturate a NIC interface (as stated above) with a single vmk adapter, so I highly recommend creating multiple vmk adapters on each of the Port groups above to make sure that you’re not only using multiple NICs, but that you can also fully saturate each of the NICs.
VMware released the vMotion TCP Stack to provided added security to vMotion capabilities, as well as introduce vMotion over multiple subnets (routed vMotion over layer 3).
Using the vMotion TCP Stack, you can isolate and have the vMotion network using it’s own gateway separate from the other vmk adapters using the traditional TCP stack on the ESXi host.
When performing a VMware vMotion on a Virtual Machine with an NVIDIA vGPU attached to it, the VM may freeze during migration. Additionally, when performing a vMotion on a VM without a vGPU, the VM does not freeze during migration.
So why is it that adding a vGPU to a VM causes it to become frozen during vMotion? This is referred to as the VM Stun Time.
I’m going to explain why this happens, and what you can do to reduce these STUN times.
VMware vMotion
First, let’s start with traditional vMotion without a vGPU attached.
VMware vMotion with vSphere
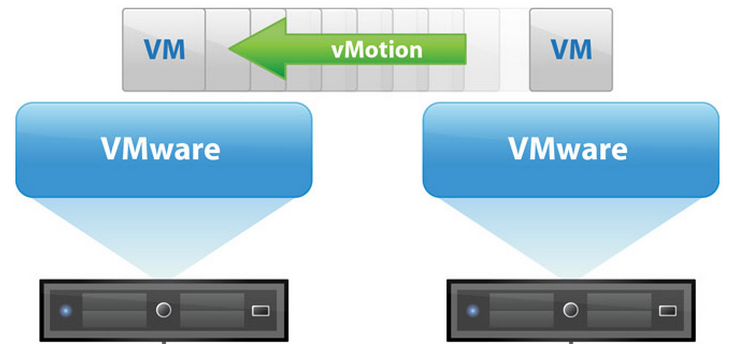
vMotion allows us to live migrate a Virtual Machine instance from one ESXi host, to another, with (visibly) no downtime. You’ll notice that I put “visibly” in brackets…
When performing a vMotion, vSphere will migrate the VM’s memory from the source to destination host and create checkpoints. It will then continue to copy memory deltas including changes blocks after the initial copy.
Essentially vMotion copies the memory of the instance, then initiates more copies to copy over the changes after the original transfer was completed, until the point where it’s all copied and the instance is now running on the destination host.
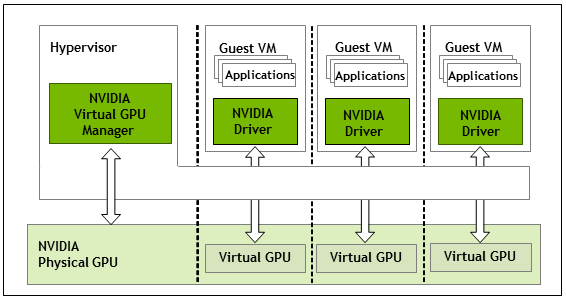
VMware vMotion with vGPU
For some time, we have had the ability to perform a vMotion with a VM that as a GPU attached to it.
VMware VMs with vGPU
However, in this situation things work slightly different. When performing a vMotion, it’s not only the system RAM memory that needs to be transferred, but the GPU’s memory (VRAM) as well.
Unfortunately the checkpoint/delta transfer technology that’s used with then system RAM isn’t available to transfer the GPU, which means that the VM has to be stunned (frozen) to stop it so that the video RAM can be transferred and then the instance can be initialized on the destination host.
STUN Time
The STUN time is essentially the time it takes to transfer the video RAM (framebuffer) from one host to another.
When researching this, you may find examples of the time it takes to transfer various sizes of VRAM. An example would be from VMware’s documentation “Using vMotion to Migrate vGPU Virtual Machines“:
Expected STUN Times for vMotion with vGPU on 10Gig vMotion NIC
However, it will always vary depending on a number of factors. These factors include:
vMotion Network Speed
vMotion Network Optimization
Multi-NIC vMotion to utilize multiple NICs
Multi-vmk vMotion to optimize and saturate single NICs
Server Load
Network Throughput
The number of VM’s that are currently being migrated with vMotion
As you can see, there’s a number of things that play in to this. If you have a single 10Gig link for vMotion and you’re migrating many VMs with a vGPU, it’s obviously going to take longer than if you were just migrating a single VM with a vGPU.
Optimizing and Minimizing vGPU STUN Time
There’s a number of things we can look at to minimize the vGPU STUN times. This includes:
Upgrading networking throughput with faster NICs
Optimizing vMotion (Configure multiple vMotion VMK adapters to saturate a NIC)
All of the above can be implemented together, which I would actually recommend.
In short, the faster we migrate the VM, the less the STUN Time will be. Check out my blog post on Optimizing VMware vMotion which includes how to perform the above recommendations.
For over a year and a half I have been working on building a custom NVMe Storage Server for my homelab. I wanted to build a high speed storage system similar to a NAS or SAN, backed with NVMe drives that provides iSCSI, NFS, and SMB Windows File Shares to my network.
The computers accessing the NVMe Storage Server would include VMware ESXi hosts, Raspberry Pi SBCs, and of course Windows Computers and Workstations.
The focus of this project is on high throughput (in the GB/sec) and IOPS.
The current plan for the storage environment is for video editing, as well as VDI VM storage. This can and will change as the project progresses.
The History
More and more businesses are using all-flash NVMe and SSD based storage systems, so I figured there’s no reason why I can’t have build and have my own budget custom all NVMe flash NAS.
This is the story of how I built my own NVMe based Storage Server.
The first version of the NVMe Storage Server consisted of the IO-PEX40152 card with 4 x 2TB Sabrent Rocket 4 NVMe drives inside of an HPE Proliant DL360p Gen8 Server. The server was running ESXi with TrueNAS virtualized, and the PCIe card passed through to the TrueNAS VM.
The results were great, the performance was amazing, and both servers had access to the NFS export via 2 x 10Gb SFP+ networking.
There were three main problems with this setup:
Virtualized – Once a month I had an ESXi PSOD. This was either due to overheating of the IO-PEX40152 card because of modifications I made, or bugs with the DL360p servers and PCIe passthrough.
NFS instead of iSCSI – Because TrueNAS was virtualized inside of the host that was using it for storage, I had to use NFS since the host virtualizing TrueNAS would also be accessing the data on the TrueNAS VM. When shutting down the host, you need to shut down TrueNAS first. NFS disconnects are handled way healthier than iSCSI disconnects (which can cause corruption even if no files are being used).
CPU Cores maxed on data transfer – When doing initial testing, I was maxing out the CPU cores assigned to the TrueNAS VM because the data transfers were so high. I needed a CPU and setup that was better fit.
Version 1 went great, but you can see some things needed to be changed. I decided to go with a dedicated server, not virtualize TrueNAS, and go for a newer CPU with a higher Ghz speed.
And so, version 2 was born (built). Keep reading and scrolling for pictures!
The Hardware
On version 2 of the project, the hardware includes:
While the ML310e Gen8 v2 server is a cheap low entry server, it’s been a fantastic team member of my homelab.
HPE Dual 10G Port 560SFP+ adapters can be found brand new in unsealed boxes on eBay at very attractive prices. Using HPE Parts inside of HPE Servers, avoids the fans from spinning up fast.
The ML310e Gen8 v2 has some issues with passing through PCIe cards to ESXi. Works perfect when not passing through.
The new NVMe Storage Server
I decided to repurpose an HPE Proliant ML310e Gen8 v2 Server. This server was originally acting as my Nvidia Grid K1 VDI server, because it supported large PCIe cards. With the addition of my new AMD S7150 x2 hacked in/on to one of my DL360p Gen8’s, I no longer needed the GRID card in this server and decided to repurpose it.
HPe ML310e Gen8 v2 with NVMe Storage
I installed the IOCREST IO-PEX40152 card in to the PCIe 16x slot, with 4 x 2TB Sabrent Rocket 4 NVME drives.
IOCREST IO-PEX40152 with GLOTRENDS M.2 NVMe SSD Heatsink on Sabrent Rocket 4 NVME
While the server has a PCIe 16x wide slot, it only has an 8x bus going to the slot. This means we will have half the capable speed vs the true 16x slot. This however does not pose a problem because we’ll be maxing out the 10Gb NICs long before we max out the 8x bus speed.
HPE ML310e Gen8 v2 with IOCREST IO-PEX40152HPE ML310e Gen8 v2 with IOCREST IO-PEX40152
I also installed an HPE Dual Port 560SFP+ NIC in to the second slot. This will allow a total of 2 x 10Gb network connections from the server to the Ubiquiti UniFi US-16-XG 10Gb network switch, the backbone of my network.
HPE ML310e Gen8 v2 with HPE 560SFP+ and 10Gig DACHPE ML310e Gen8 v2 with HPE 560SFP+ and 10Gig DAC
The Server also have 4 x Hot Swappable HD bays on the front. When configured in HBA mode (via the BIOS), these are accessible by TrueNAS and can be used. I plan on populating these with 4 x 4TB HPE MDL SATA Hot Swappable drives to act as a replication destination for the NVMe pool and/or slower magnetic long-term storage.
HPE ML310e Gen8 v2 with Hotswap Drive bays
I may also try to give WD RED Pro drives a try, but I’m not sure if they will cause the fans to speed up on the server.
TrueNAS Installation and Configuration
For the initial Proof-Of-Concept for version 2, I decided to be quick and dirty and install it to a USB stick. I also waited until I installed TrueNAS on to the USB stick and completed basic configuration before installing the Quad NVMe PCIe card and 10Gb NIC. I’m using a USB 3.0 port on the back of the server for speed, as I can’t verify if the port on the motherboard is USB 2 or USB 3.
TrueNAS USB Stick on HPE ML310e Gen8 v2
TrueNAS installation worked without any problems whatsoever on the ML310e. I configured the basic IP, time, accounts, and other generic settings. I then proceeded to install the PCIe cards (storage and networking).
TrueNAS Installed on NVMe Storage Server
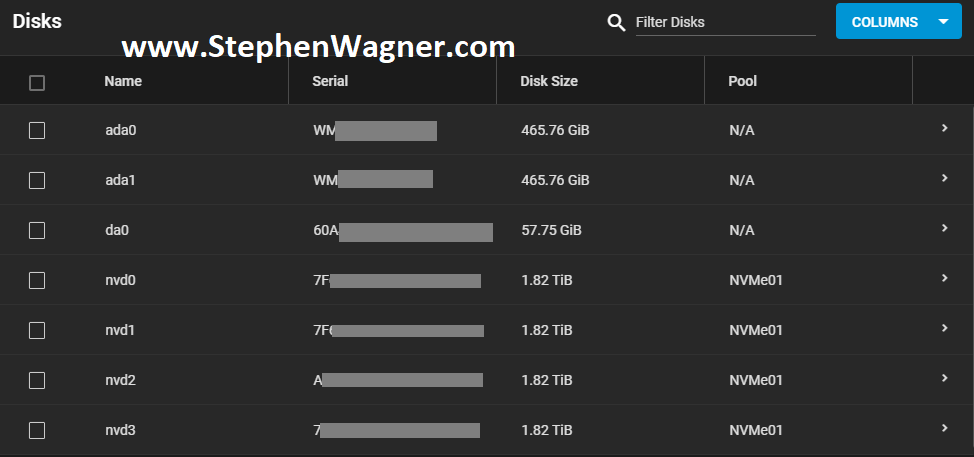
All NVMe drives were recognized, along with the 2 HDDs I had in the front Hot-swap bays (sitting on an HP B120i Controller configured in HBA mode).
TrueNAS NVMe Disks
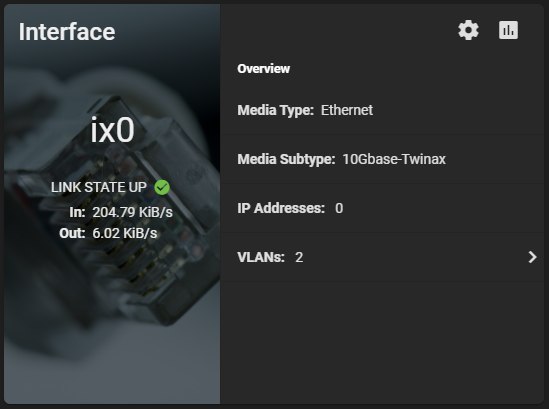
The 560SFP+ NIC also was detected without any issues and available to configure.
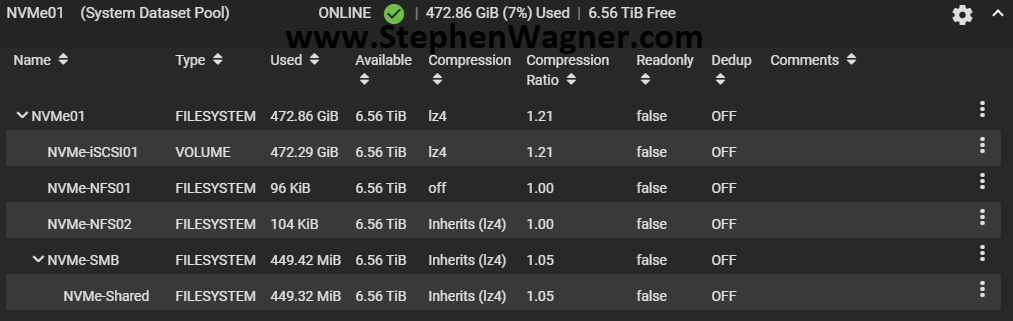
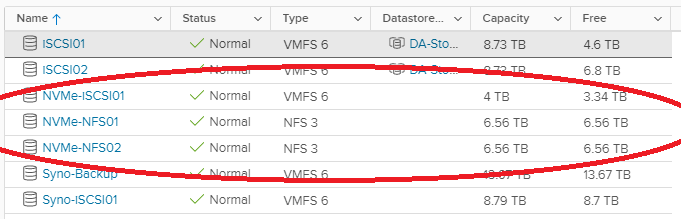
I created a striped pool (no redundancy) of all 4 x 2TB NVMe drives. This gave us around 8TB of usable high speed NVMe storage. I also created some datasets and a zVOL for iSCSI.
NVMe TrueNAS Storage Pool with Datasets and zVol
I chose to go with the defaults for compression to start with. I will be testing throughput and achievable speeds in the future. You should always test this in every and all custom environments as the results will always vary.
Network Configuration
Initial configuration was done via the 1Gb NIC connection to my main LAN network. I had to change this as the 10Gb NIC will be directly connected to the network backbone and needs to access the LAN and Storage VLANs.
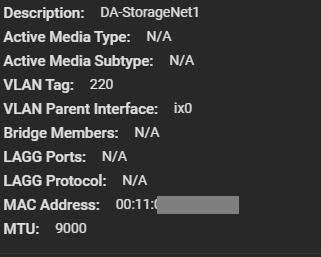
I went ahead and configured a VLAN Interface on VLAN 220 for the Storage network. Connections for iSCSI and NFS will be made on this network as all my ESXi servers have vmknics configured on this VLAN for storage. I also made sure to configure an MTU of 9000 for jumbo frames (packets) to increase performance. Remember that all hosts must have the same MTU to communicate.
10Gb NIC on Storage VLAN
Next up, I had to create another VLAN interface for the LAN network. This would be used for management, as well as to provide Windows File Share (SMB/Samba) access to the workstations on the network. We leave the MTU on this adapter as 1500 since that’s what my LAN network is using.
10Gb NIC on LAN VLAN
As a note, I had to delete the configuration for the existing management settings (don’t worry, it doesn’t take effect until you hit test) and configure the VLAN interface for my LANs VLAN and IP. I tested the settings, confirmed it was good, and it was all setup.
At this point, only the 10Gb NIC is now being used so I went ahead and disconnected the 1Gb network cable.
Sharing Setup and Configuration
It’s now time to configure the sharing protocols that will be used. As mentioned before, I plan on deploying iSCSI, NFS, and Windows File Shares (SMB/Samba).
iSCSI and NFS Configuration
Normally, for a VMware ESXi virtualization environment, I would always usually prefer iSCSI based storage, however I also wanted to configure NFS to test throughput of both with NVMe flash storage.
Earlier, I created the datasets for all my my NFS exports and a zVOL volume for iSCSI.
Note, that in order to take advantage of the VMware VAAI storage directives (enhancements), you must use a zVOL to present an iSCSI target to an ESXi host.
For NFS, you can simply create a dataset and then export it.
For iSCSI, you need to create a zVol and then configure the iSCSI Target settings and make it available.
SMB (Windows File Shares)
I needed to create a Windows File Share for file based storage from Windows computers. I plan on using the Windows File Share for high-speed storage of files for video editing.
Using the dataset I created earlier, I configured a Windows Share, user accounts, and tested accessing it. Works perfect!
Connecting the host
Connecting the ESXi hosts to the iSCSI targets and the NFS exports is done in the exact same way that you would with any other storage system, so I won’t be including details on that in this post.
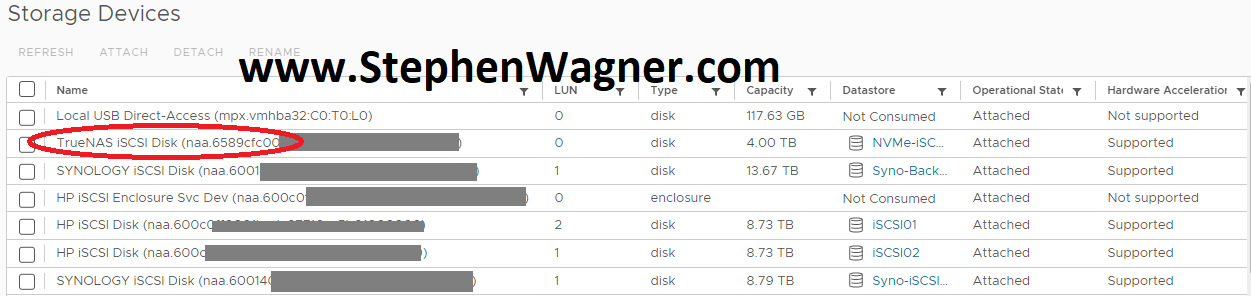
We can clearly see the iSCSI target and NFS exports on the ESXi host.
TrueNAS NVMe iSCSI Target on VMware ESXi Host
NVMe iSCSI and NFS ESXi Datastores
To access Windows File Shares, we log on and map the network share like you would normally with any file server.
Testing
For testing, I moved (using Storage vMotion) my main VDI desktop to the new NVMe based iSCSI Target LUN on the NVMe Storage Server. After testing iSCSI, I then used Storage vMotion again to move it to the NFS datastore. Please see below for the NVMe storage server speed test results.
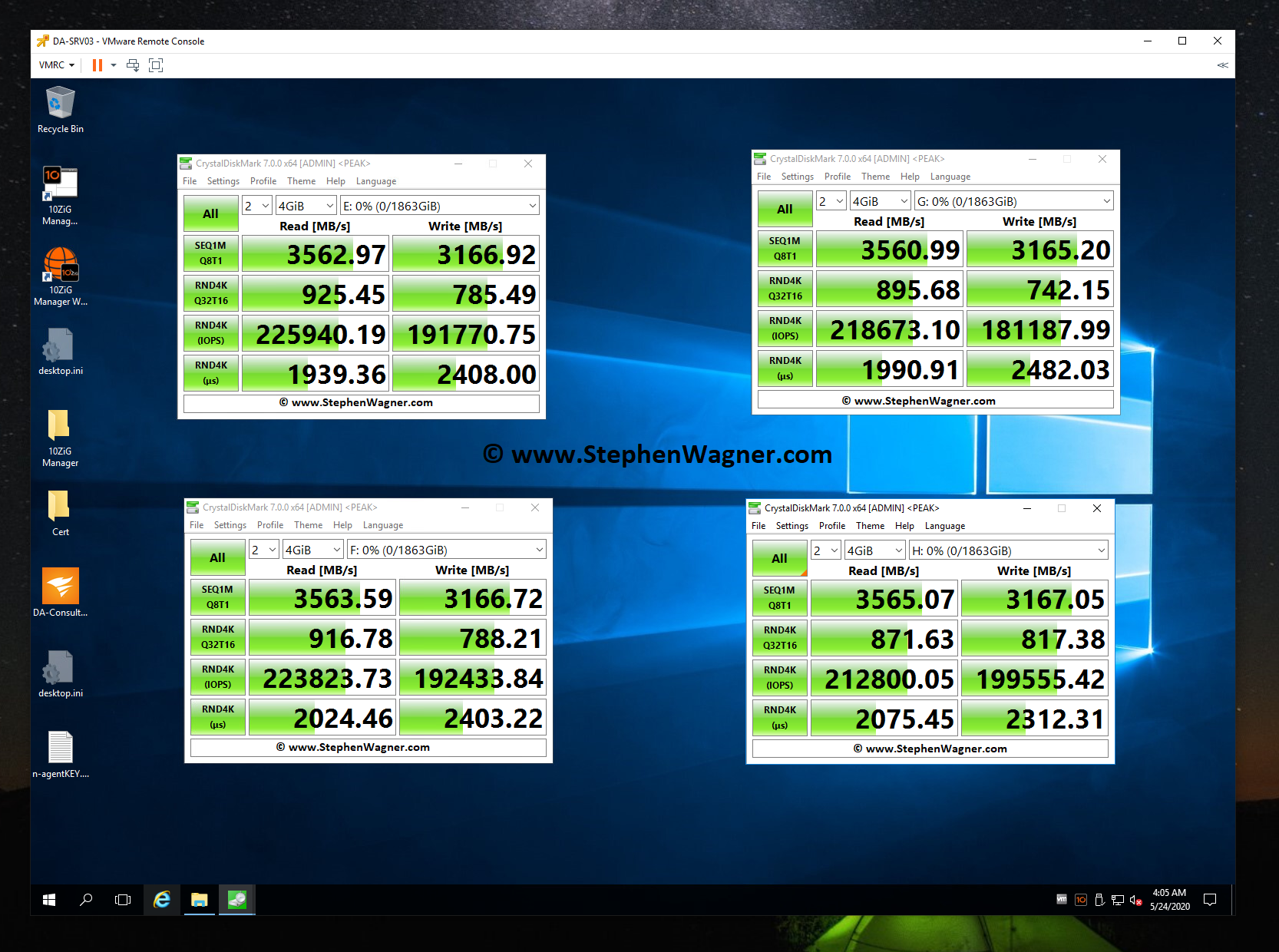
CrystalDiskMark testing an IOCREST IO-PEX40152 and Sabrent Rocket 4 NVME SSD
CrystalDiskMark testing IOPS on an IOCREST IO-PEX40152 and Sabrent Rocket 4 NVME SSD
Note, that when I performed these tests, my CPU was maxed out and limiting the actual throughput. Even then, these are some fairly impressive speeds. Also, these tests were directly testing each NVMe drive individually.
Moving on to the NVMe Storage Server, I decided to test iSCSI NVMe throughput and NFS NVMe throughput.
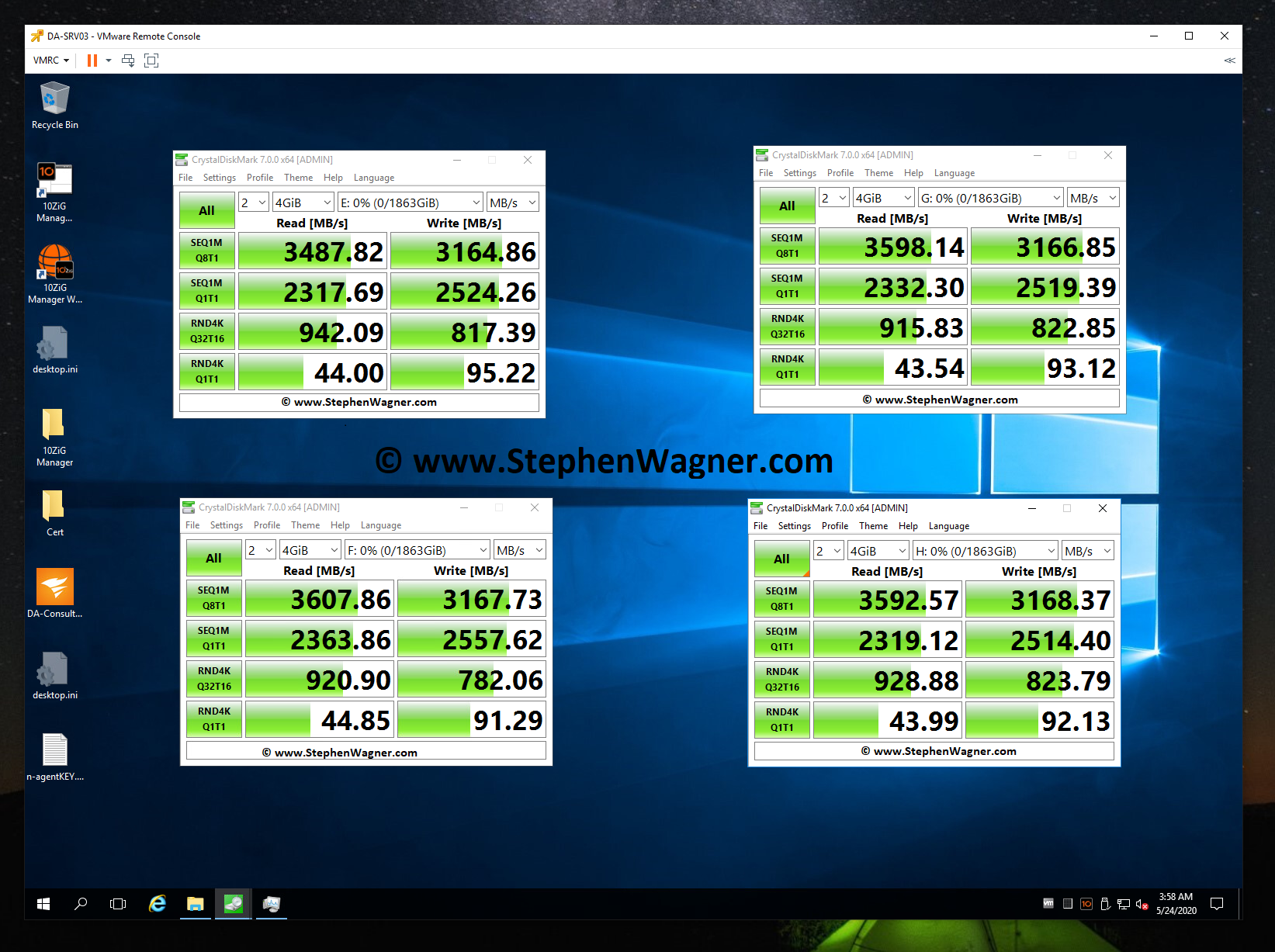
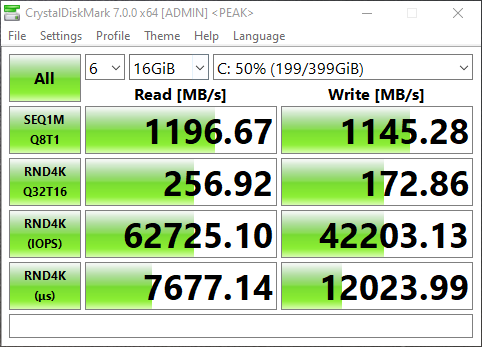
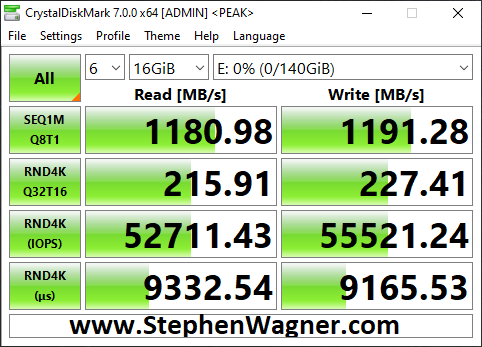
I opened up CrystalDiskMark and started a generic test, running a 16GB test file a total of 6 times on my VDI VM sitting on the iSCSI NVMe LUN.
NVMe Storage Server iSCSI Benchmark with CrystalDiskMark
You can see some impressive speeds maxing out the 10Gb NIC with crazy performance of the NVME storage:
1196MB/sec READ
1145.28MB/sec WRITE (Maxing out the 10GB NIC)
62,725.10 IOPS READ
42,203.13 IOPS WRITE
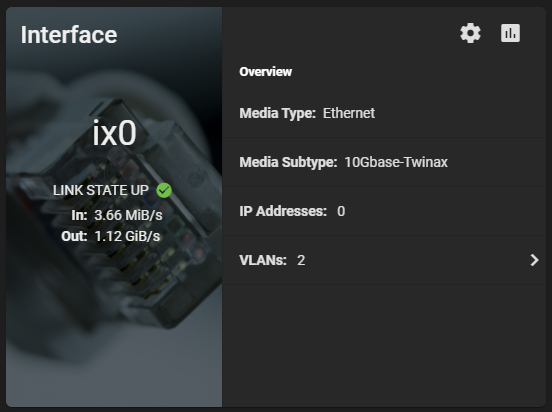
Additionally, here’s a screenshot of the ix0 NIC on the TrueNAS system during the speed test benchmark: 1.12 GiB/s.
TrueNAS NVME Maxing out 10Gig NIC
And remember this is with compression. I’m really excited to see how I can further tweak and optimize this, and also what increases will come with configuring iSCSI MPIO. I’m also going to try to increase the IOPS to get them closer to what each individual NVMe drive can do.
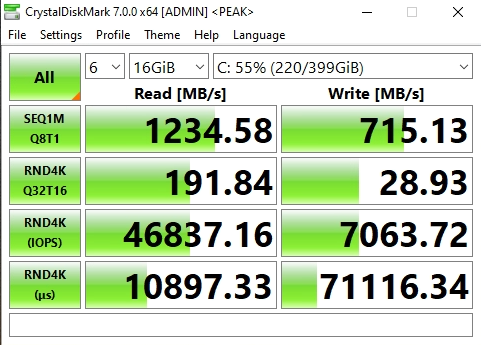
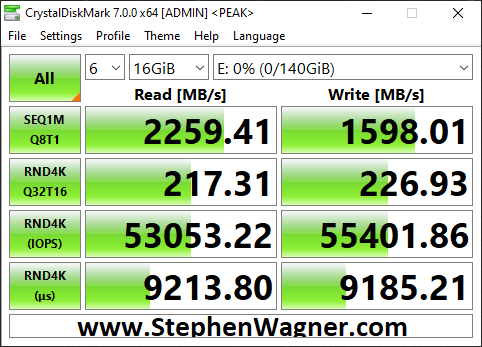
Now on to NFS, the results were horrible when moving the VM to the NFS Export.
NVMe Storage Server NFS Benchmark with CrystalDiskMark
You can see that the read speed was impressive, but the write speed was not. This is partly due to how writes are handled with NFS exports.
Clearly iSCSI is the best performing method for ESXi host connectivity to a TrueNAS based NVMe Storage Server. This works perfect because we’ll get the VAAI features (like being able to reclaim space).
iSCSI MPIO Speed Test
This is more of an update… I was finally able to connect, configure, and utilize the 2nd 10Gbe port on the 560SFP+ NIC. In my setup, both hosts and the TrueNAS storage server all have 2 connections to the switch, with 2 VLANs and 2 subnets dedicated to storage. Check out the before/after speed tests with enabling iSCSI MPIO.
TrueNAS NVME iSCSI MPIO BeforeTrueNAS NVME iSCSI MPIO AfterBefore and After enabling iSCSI MPIO on TrueNAS with NVME Storage
As you can see I was able to essentially double my read speeds (again maxing out the networking layer), however you’ll notice that the write speeds maxed out at 1598MB/sec. I believe we’ve reached a limitation of the CPU, PCIe bus, or something else inside of the server. Note, that this is not a limitation of the Sabrent Rocket 4 NVME drives, or the IOCREST NVME PCIe card.
Moving Forward
I’ve had this configuration running for around a week now with absolutely no issues, no crashes, and it’s been very stable.
Using a VDI VM on NVMe backed storage is lightning fast and I love the experience.
I plan on running like this for a little while to continue to test the stability of the environment before making more changes and expanding the configuration and usage.
Future Plans (and Configuration)
Drive Bays
I plan to populate the 4 hot-swappable drive bays with HPE 4TB MDL drives. Configured with RaidZ1, this should give me around 12TB usable storage. I can use this for file storage, backups, replication, and more.
NVMe Replication
This design was focused on creating non-redundant extremely fast storage. Because I’m limited to a total of 4 NVMe disks in this design, I chose not to use RaidZ and striped the data. If one NVMe drive is lost, all data is lost.
I don’t plan on storing anything important, and at this point the storage is only being used for VDI VMs (which are backed up), and Video editing.
If I can populate the front drive bays, I can replicate the NVMe storage to the traditional HDD storage on a frequent basis to protect against failure to some level or degree.
Version 3 of the NVMe Storage Server
More NVMe and Bigger NVMe – I want more storage! I want to test different levels of RaidZ, and connect to the backbone at even faster speeds.
NVME Drives with PLP (Power Loss Prevention) for data security and protection.
Dual Power Supply
Let me know your thoughts and ideas on this setup!
I’ve noticed in a few situations where an ESXi host is marked as “unresponsive” or “disconnected” inside of vCenter due to issues occurring on that host (or connected hardware). This recently happened again with a customer and is why I’m writing this article at this very moment.
In these situations, usually all normal means of managing, connecting, or troubleshooting the host are unavailable. Usually in cases like this ESXi administrators would simply reset the host.
However, I’ve found hosts can often be rescued without requiring an ungraceful restart or reset.
Observations
In these situations, it can be observed that:
The ESXi host is in a unresponsive to disconnected state to vCenter Server.
Connecting to the ESXi host directly does not work as it either doesn’t acknowledge HTTPS requests, or comes up with an error.
Accessing the console of the ESXi host isn’t possible as it appears frozen.
While the ESXi host is unresponsive, the virtual machines are still online and available on the network.
Troubleshooting
In the few situations I’ve noticed this occurring, troubleshooting is possible but requires patience. Consider the following:
When trying to access the ESXi console, give it time after hitting enter or selecting a value. If there’s issues on the host such as commands pending, tasks pending, or memory issues, the console may actually respond if you give it 30 seconds to 5 minutes after selecting an item.
With the above in mind, attempt to enable console access (preferably console and not SSH). The logins may take some time (30 seconds to 5 minutes after typing in the password), but you might be able to gain troubleshooting access.
Check the SAN, NAS, and any shared storage… In one instance, there were issues with a SAN and datastore that froze 2 VMs. The Queued commands to the SAN caused the ESXi host to become unresponsive.
There may be memory issues with the ESXi instance. The VMs are fine, however an agent, driver, or piece of software may be causing the hypervisor layer to become unresponsive.
If there are storage issues, do what you can. In one of the cases above, we had to access the ESXi console, issue a “kill -9” to the VM, and then restart the SAN. We later found out there was issues with the SAN and corrupted virtual machines. The moment the SAN was restarted, the ESXi host became responsive, connected to the vCenter server and could be managed.
In another instance, on an older version of ESXi there was an HPE agentless management driver/service that was consuming the ESXi hosts memory continuously causing the memory to overflow, the host to fill the swap and become unresponsive. Eventually after gracefully shutting down the VMs, I was able to access the console, kill the service, and the host become responsive.
We’ve all been in the situation where we need to install a driver, vib file, or check “esxtop”. Many advanced administration tasks on ESXi need to be performed via shell access, and to do this you either need a console on the physical ESXi host, an SSH session, or use the Remote vCLI.
In this blog post, I’m going to be providing a quick “How to” enable SSH on an ESXi host in your VMware Infrastructure using the vCenter flash-based web administration interface. This will allow you to perform the tasks above, as well as use the “esxcli” command which is frequently needed.
This method should work on all vCenter versions up to 6.7, and ESXi versions up to 6.7.
How to Enable SSH on an ESXi Host Server
Log on to your vCenter server.
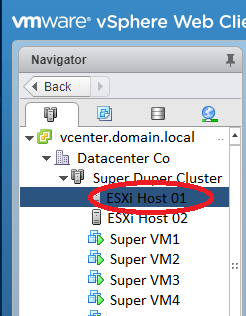
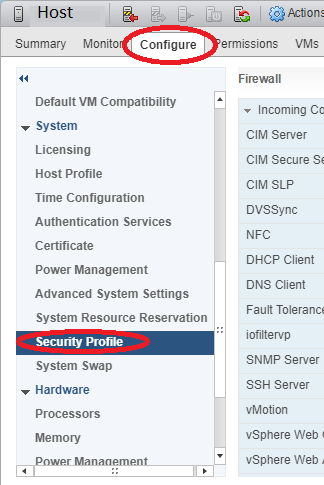
On the left hand “Navigator” pane, select the ESXi host.
On the right hand pane, select the “Configure” tab, then “Security Profile” under “System.
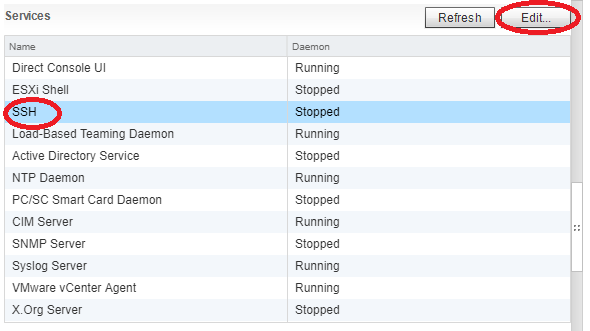
Scroll down and look for “Services” further to the right and select “Edit”.
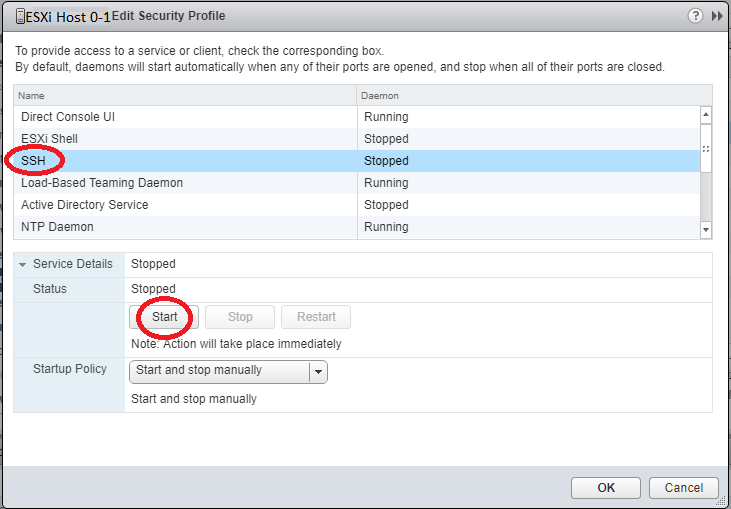
In the “Edit Security Profile” window, select and highlight “SSH” and then click “Start”.
Click “Ok”.
This method can also be used to stop, restart, and change the startup policy to enable or disable SSH starting on boot.
Congratulations, you can now SSH in to your ESXi host!
This website uses cookies to improve your experience. We'll assume you're ok with this, but you can opt-out if you wish.
Do you accept the use of cookies and accept our privacy policy? AcceptRejectCookie and Privacy Policy
Privacy & Cookies Policy
Privacy Overview
This website uses cookies to improve your experience while you navigate through the website. Out of these cookies, the cookies that are categorized as necessary are stored on your browser as they are essential for the working of basic functionalities of the website. We also use third-party cookies that help us analyze and understand how you use this website. These cookies will be stored in your browser only with your consent. You also have the option to opt-out of these cookies. But opting out of some of these cookies may have an effect on your browsing experience.