Normally, any VMs that are NVIDIA vGPU enabled have to be manually migrated with manual vMotion if a host is placed in to maintenance mode, to evacuate the host. While we may have grown accustomed to this, there is a better way, with vGPU Enabled VM DRS Evacuation during Maintenance mode!
A new feature that was introduced with vSphere 7.0 U3f, was the ability to configure and allow automatic vMotion of VMs with vGPUs, meaning that DRS can now migrate your VDI and AI/ML vGPU enabled workloads when hosts are placed in to maintenance mode. This also allows you to streamline remediation with vLCM when updating vGPU enabled hosts running vGPU enabled VMs.
Additionally, as of vSphere 8.0 U2, DRS can now estimate the STUN times required for vMotion of vGPU enabled VMs, and control whether automatic DRS vMotion’s are allowed. This STUN time limit can be set buy an administrator.
Enable automatic vMotion evacuation of vGPU enabled VMs
To enable the automatic vMotion of vGPU enabled VMs on your vSphere Cluster:
Navigate to your vSphere Cluster.
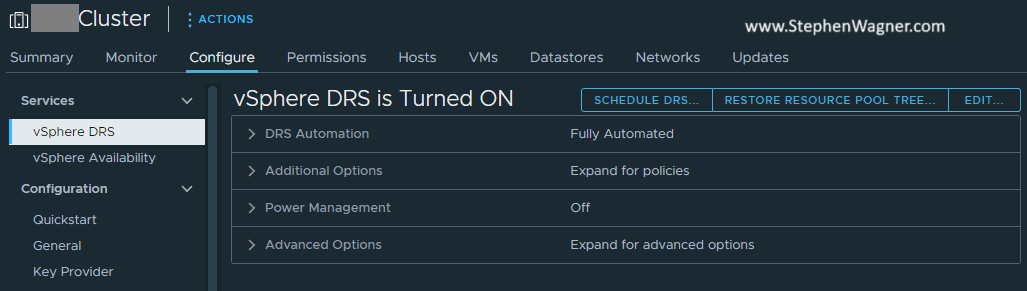
Click on the “Configure” Tab, and then select “vSphere DRS”, and click “Edit”.
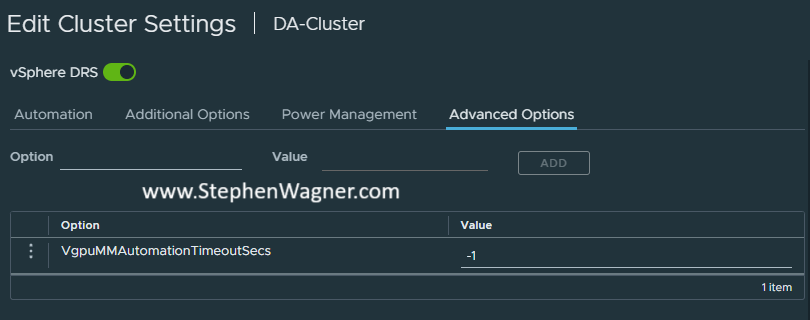
Navigate to the “Advanced Options” tab.
Add “VgpuMMAutomationTimeoutSecs” and set to “-1”.
After performing the above, when you place a host with vGPU enabled Virtual Machines in to Maintenance Mode, vSphere DRS will evacuate and migrate the VMs to other hosts in the cluster that have the required hardware.
If you attempt to place a host in to Maintenance Mode without enabling automatic vMotion of vGPU enabled VMs, it will fail with the error: “DRS failed to generate a vMotion recommendation for a virtual machine on a host entering Maintenance Mode“.
Enable and Configure vGPU STUN Time Estimate and Limits
If you are running vSphere 8U2 or higher, you can enable vGPU STUN time estimation and limits for DRS on the vGPU enabled cluster. Similar to the instructions above, we can add and configure two variables to the vSphere DRS cluster “Advanced Options”.
To enable STUN time estimation, add PassthroughDrsAutomation and set to “1”.
To override the default vMotion STUN time limit of 100 seconds, add VmDevicesStunTimeTolerated and set it to your preferred maximum number of seconds. Alternatively, you can set this limit Per VM by navigating to the VM in vSphere and adding this variable under the “VM Options” “Advanced Settings” section.
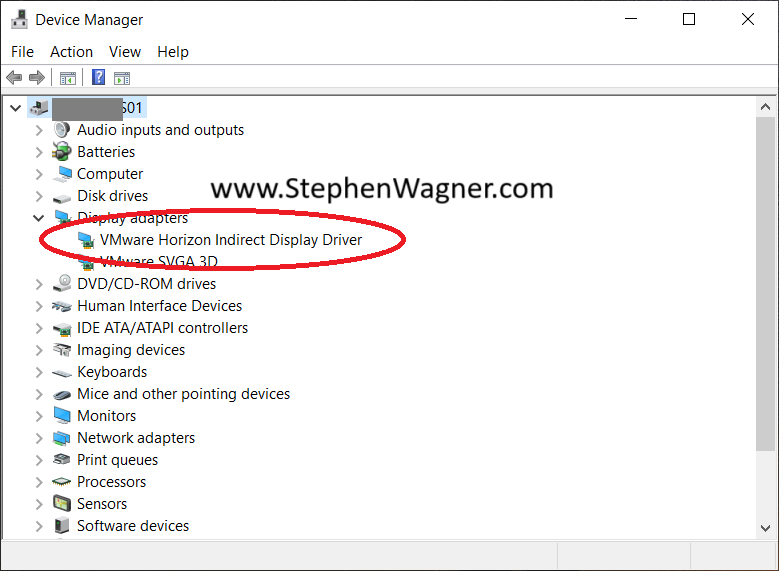
You may experience GPU issues with the VMware Horizon Indirect Display Driver in your environment when using 3rd party applications which incorrectly utilize the incorrect display adapter. This results with the inability to use and/or run GPU accelerated workloads including VDI, AI, and ML.
This issue effects NVIDIA vGPU (both vGPU and vDGA passthrough), AMD MxGPU, and Intel Data Center GPU Flex GPUs using SR-IOV, in any deployment where the VMware Indirect Display Driver is installed.
When this issue occurs, the application will incorrectly query the capabilities of the VMware Indirect Display Adapter instead of the GPU that is presented to the VM, resulting in a scenario where the application isn’t aware of the capabilities of the GPU you are utilizing, failing to utilize the GPU, and hardware acceleration, such as hardware encoding (NVENC) and hardware decoding.
What is the VMware Horizon Indirect Display Driver
The VMware Horizon Indirect Display Driver, also known as the VMware Indirect Display Driver, is a “virtual” display driver that isn’t bound to a specific hypervisor, and works with many deployments because of the lack of that limitation.
GPU Issues with the VMware Horizon Indirect Display Driver Enabled
This driver is installed with the VMware Horizon agent, and can work in conjunction with hardware acceleration, including GPUs (such as NVIDIA vGPU, AMD MxGPU, and Intel Data Center GPUs using SR-IOV).
Under normal circumstances, the VMware Horizon Indirect Display Driver is prioritized as a fallback driver for remoting protocols, except in environments where no hypervisor or GPU display drivers are available (like Horizon Cloud on Azure) in which case it would become the priority.
The Problem
Applications designed to use a GPU, may not be able to correctly identify which display adapter to use on the VM. While you may have a GPU, vGPU, or 3D acceleration in your environment, the application may be unaware of the device and/or its capabilities.
This is caused by the application either not correctly using the preferred primary display adapter (GPU and/or vGPU), or not being designed to handle multiple display adapters (and drivers).
Example Scenario:
When using CyberLink PowerDirector 360 in a VMware Horizon environment with an NVIDIA vGPU, the application will query the VM’s Windows instance for hardware acceleration capabilities, specifically hardware encoding, hardware decoding, and use of APIs like NVIDIA’s NVENC encoder. In this scenario, while the VM does have an NVIDIA vGPU workstation profile attached with a valid NVIDIA RTX Virtual Workstation (vWS) license, the application is only aware of the VMware Indirect Display Driver and it’s capabilities. This results in all hardware accelerated encoding and decoding capabilities to be disabled.
Example Symptoms
3D Acceleration not detected by application
CUDA Cores not available for application
OpenCL not available
DirectX and Direct3D usage unavailable
In all scenarios, the VM will appear to have 3D acceleration, however one or multiple applications won’t have access.
The Solution
Thanks to the design of the VMware Indirect Display Driver, it should be prioritized in a fashion that it’s used only when other display drivers aren’t available (including NVIDIA vGPU), or system resources aren’t available; however, some 3rd party application may not be able to reference the prioritization, or support multi-GPU (multi display driver), resulting in the incorrect display adapter being used.
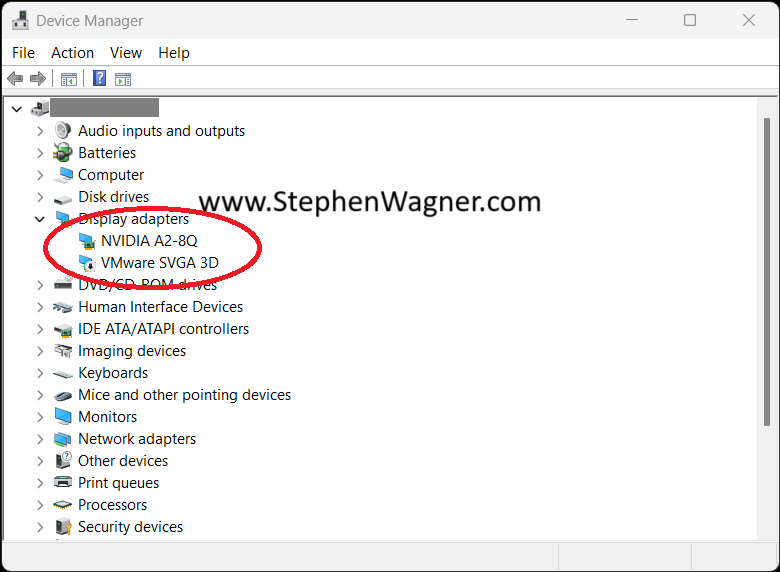
As a workaround, you can remove the VMware Indirect Display Driver from the Windows instance running in the VM.
NVIDIA vGPU with VMware Horizon Indirect Display Driver Removed
Please note that simply disabling the “VMware Horizon Indirect Display Driver” will not suffice. A full removal (Right Click, “Uninstall Device”) is required to workaround this issue. Additionally, upgrading or re-installing the VMware Horizon Agent will re-install the VMware Indirect Display Driver.
In May of 2023, NVIDIA released the NVIDIA GPU Manager for VMware vCenter. This appliance allows you to manage your NVIDIA vGPU Drivers for your VMware vSphere environment.
Since the release, I’ve had a chance to deploy it, test it, and use it, and want to share my findings.
In this post, I’ll cover the following (click to skip ahead):
The NVIDIA GPU Manager is an (OVA) appliance that you can deploy in your VMware vSphere infrastructure (using vCenter and ESXi) to act as a driver (and update) repository for vLCM (vSphere Lifecycle Manager).
In addition to acting as a repo for vLCM, it also installs a plugin on your vCenter that provides a GUI for browsing, selecting, and downloading NVIDIA vGPU host drivers to the local repo running on the appliance. These updates can then be deployed using LCM to your hosts.
In short, this allows you to easily select, download, and deploy specific NVIDIA vGPU drivers to your ESXi hosts using vLCM baselines or images, simplifying the entire process.
Supported vSphere Versions
The NVIDIA GPU Manager supports the following vSphere releases (vCenter and ESXi):
VMware vSphere 8.0 (and later)
VMware vSphere 7.0U2 (and later)
The NVIDIA GPU Manager supports vGPU driver releases 15.1 and later, including the new vGPU 16 release version.
How to deploy and configure the NVIDIA GPU Manager for VMware vCenter
To deploy the NVIDIA GPU Manager Appliance, we have to download an OVA (from NVIDIA’s website), then deploy and configure it.
See below for the step by step instructions:
Download the NVIDIA GPU Manager
Log on to the NVIDIA Application Hub, and navigate to the “NVIDIA Licensing Portal” (https://nvid.nvidia.com).
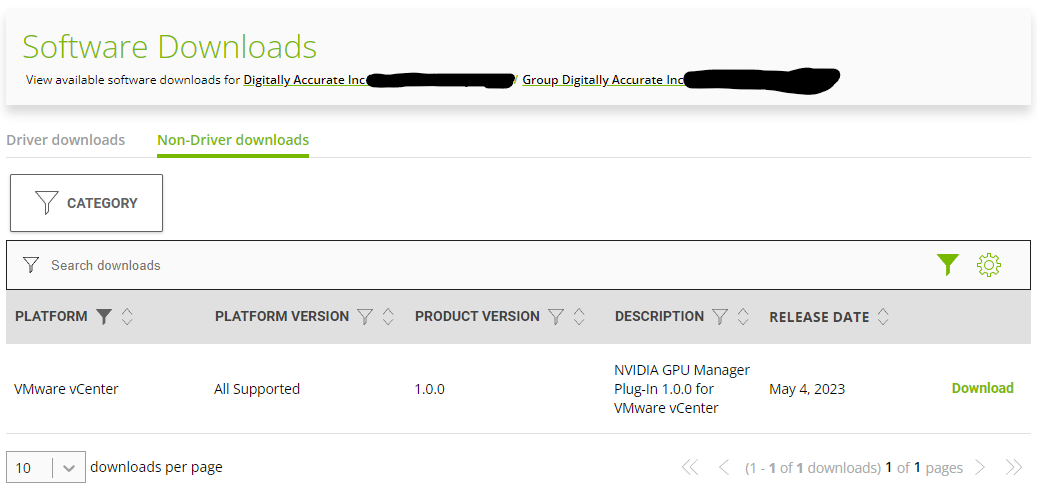
Navigate to “Software Downloads” and select “Non-Driver Downloads”
Change Filter to “VMware vCenter” (there is both VMware vSphere, and VMware vCenter, pay attention to select the correct).
To the right of “NVIDIA GPU Manager Plug-in 1.0.0 for VMware vCenter”, click “Download” (see below screenshot).
NVIDIA GPU Manager Download Page
After downloading the package and extracting, you should be left with the OVA, along with Release Notes, and the User Guide. I highly recommend reviewing the documentation at your leisure.
Deploy and Configure the NVIDIA GPU Manager
We will now deploy the NVIDIA GPU Manager OVA appliance:
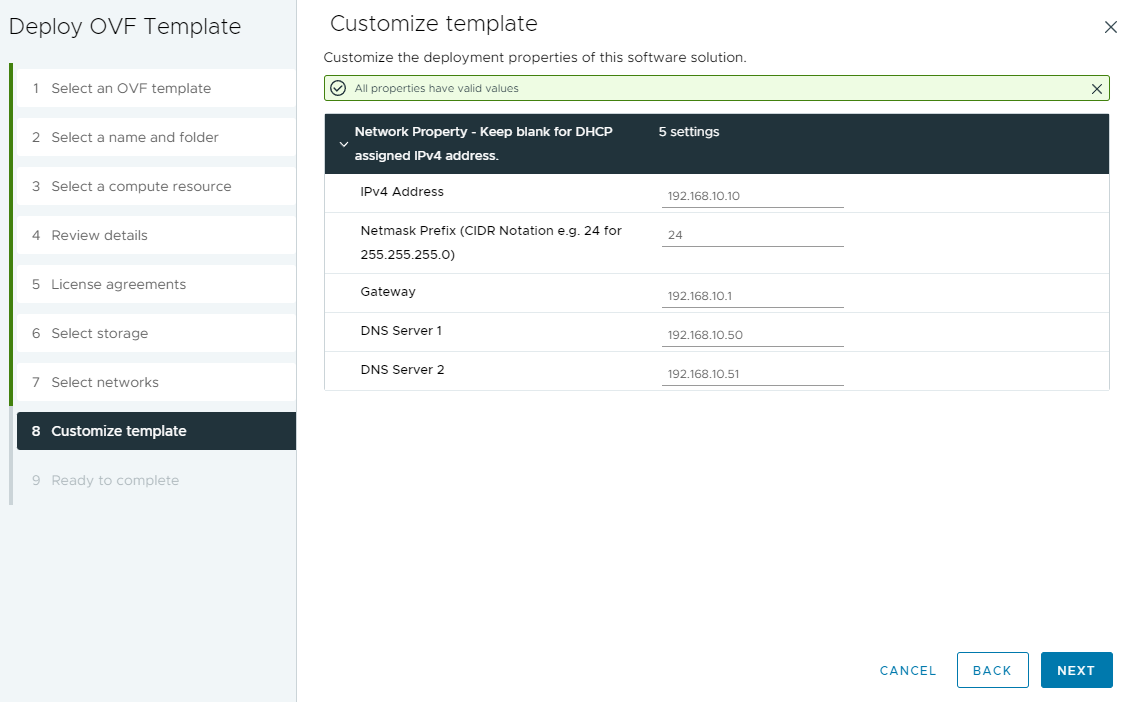
Deploy the OVA to either a cluster with DRS, or a specific ESXi host. In vCenter either right click a cluster or host, and select “Deploy OVF Template”. Choose the GPU Manager OVA file, and continue with the wizard.
Configure Networking for the Appliance
You’ll need to assign an IP Address, and relevant networking information.
I always recommend creating DNS (forward and reverse entries) for the IP.
Finally, power on Appliance.
We must now create a role and service account that the GPU Manager will use to connect to the vCenter server.
While the vCenter Administrator account will work, I highly recommend creating a service account specifically for the GPU Manager that only has the required permissions that are necessary for it to function.
Log on to your vCenter Server
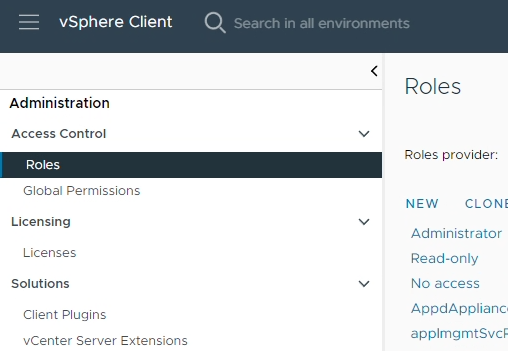
Click on the hamburger menu item on the top left, and open “Administration”.
Under “Access Control” select Roles.
Select New to create a new role. We can call it “NVIDIA Update Services”.
***PLEASE NOTE: The above permissions were provided in the documentation and did not work for me (resulted in an insufficient privileges error). To resolve this, I chose “Select All” for “VMware vSphere Lifecycle Manager”, which resolved the issue.***
Save the Role
On the left hand side, navigate to “Users and Groups” under “Single Sign On”
Change the domain to your local vSphere SSO domain (vsphere.local by default)
Create a new user account for the NVIDIA appliance, as an example you could use “nvidia-svc”, and choose a secure password.
Navigate to “Global Permissions” on the left hand side, and click “Add” to create a new permission.
Set the domain, and choose the new “nvidia-svc” service account we created, and set the role to “NVIDIA Update Services”, and check “Propagate to Children”.
You have now configured the service account.
Now, we will perform the initial configuration of the appliance. To configure the application, we must do the following:
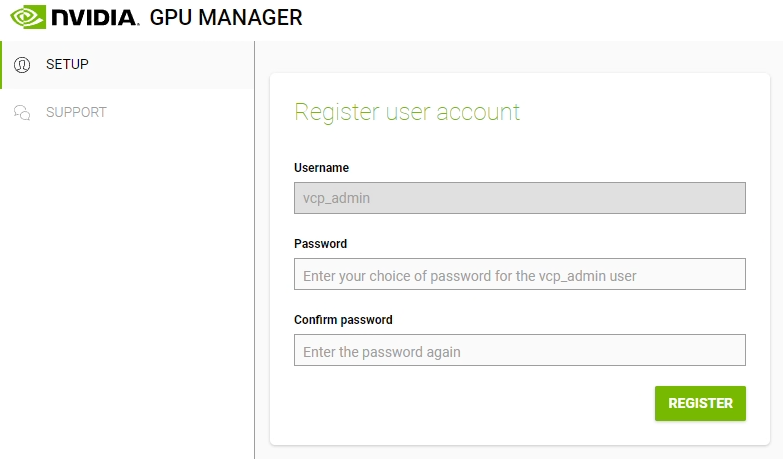
Access the appliance using your browser and the IP you configured above (or FQDN)
Create a new password for the administrative “vcp_admin” account. This account will be used to manage the appliance.
A secret key will be generated that will allow the password to be reset, if required. Save this key somewhere safe.
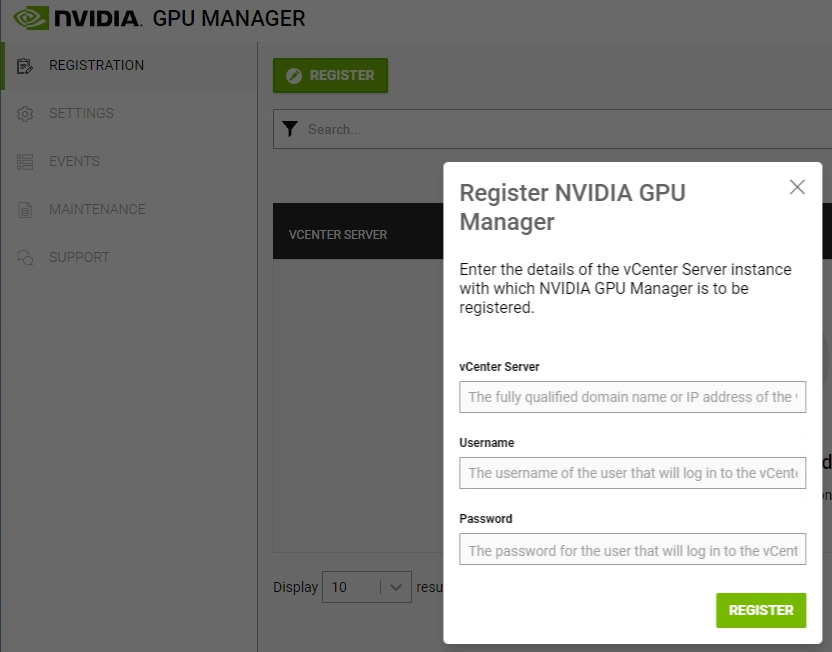
We must now register the appliance (and plugin) with our vCenter Server. Click on “REGISTER”.
Enter the FQDN or IP of your vCenter server, the NVIDIA Service account (“nvidia-svc” from example), and password.
Once the GPU Manager is registered with your vCenter server, the remainder of the configuration will be completed from the vCenter GPU.
The registration process will install the GPU Manager Plugin in to VMware vCenter
The registration process will also configure a repository in LCM (this repo is being hosted on the GPU manager appliance).
We must now configure an API key on the NVIDIA Licensing portal, to allow your GPU Manager to download updates on your behalf.
Open your browser and navigate to https://nvid.nvidia.com. Then select “NVIDIA LICENSING PORTAL”. Login using your credentials.
On the left hand side, select “API Keys”.
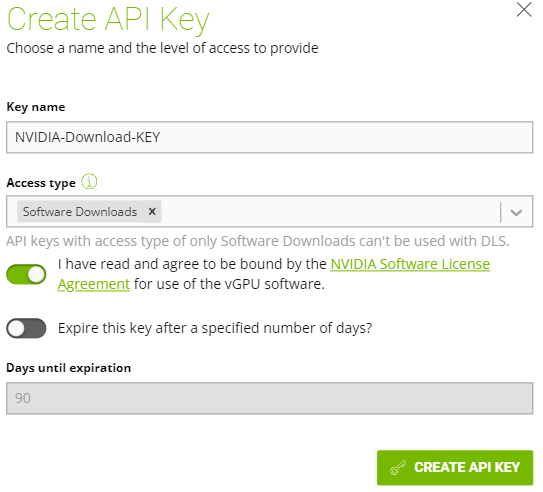
On the upper right hand, select “CREATE API KEY”.
Give the key a name, and for access type choose “Software Downloads”. I would recommend extending the key validation time, or disabling key expiration.
The key should now be created.
Click on “view api key”, and record the key. You’ll need to enter this in later in to the vCenter GPU Manager plugin.
And now we can finally log on to the vCenter interface, and perform the final configuration for the appliance.
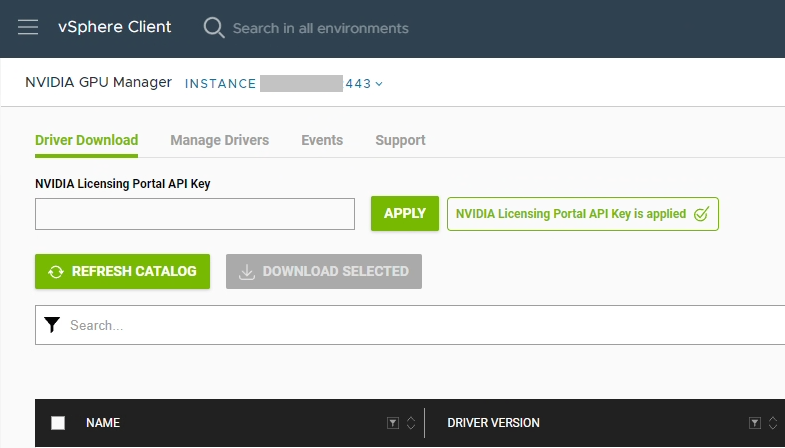
Log on to the vCenter client, click on the hamburger menu, and select “NVIDIA GPU Manager”.
Enter the API key you created above in to the “NVIDIA Licensing Portal API Key” field, and select “Apply”.
The appliance should now be fully configured and activated.
Configuration is complete.
We have now fully deployed and completed the base configuration for the NVIDIA GPU Manager.
Using the NVIDIA GPU Manager to manage, update, and deploy vGPU drivers to ESXi hosts
In this section, I’ll be providing an overview of how to use the NVIDIA GPU Manager to manage, update, and deploy vGPU drivers to ESXi hosts. But first, lets go over the workflow…
The workflow is a simple one:
Using the vCenter client plugin, you choose the drivers you want to deploy. These get downloaded to the repo on the GPU Manager appliance, and are made available to Lifecycle Manager.
You then use Lifecycle Manager to deploy the vGPU Host Drivers to the applicable hosts, using baselines or images.
As you can see, there’s not much to it, despite all the configuration we had to do above. While it is very simple, it simplifies management quite a bit, especially if you’re using images with Lifecycle Manager.
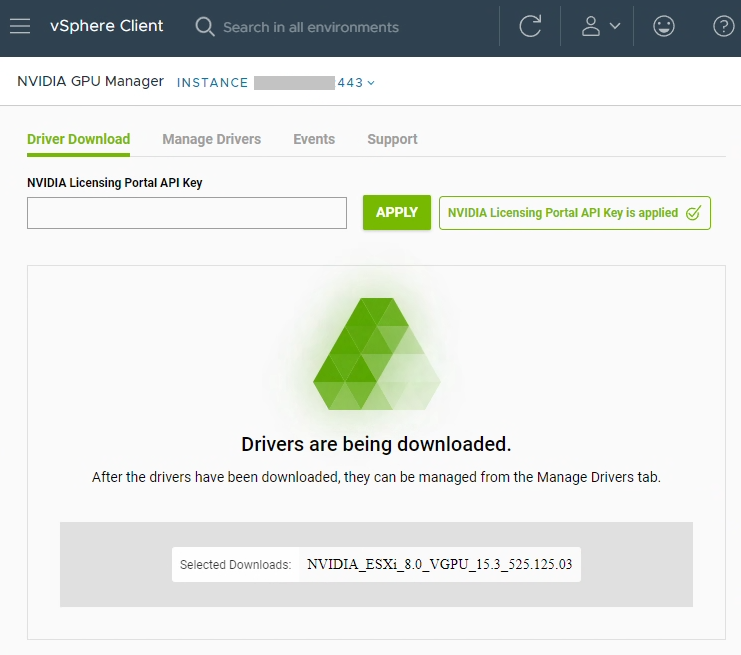
To choose and download the drivers, load up the plugin, use the filters to filter the list, and select your driver to download.
NVIDIA GPU Manager downloading vGPU Driver
As you can see in the example, I chose to download the vGPU 15.3 host driver. Once completed, it’ll be made available in the repo being hosted on the appliance.
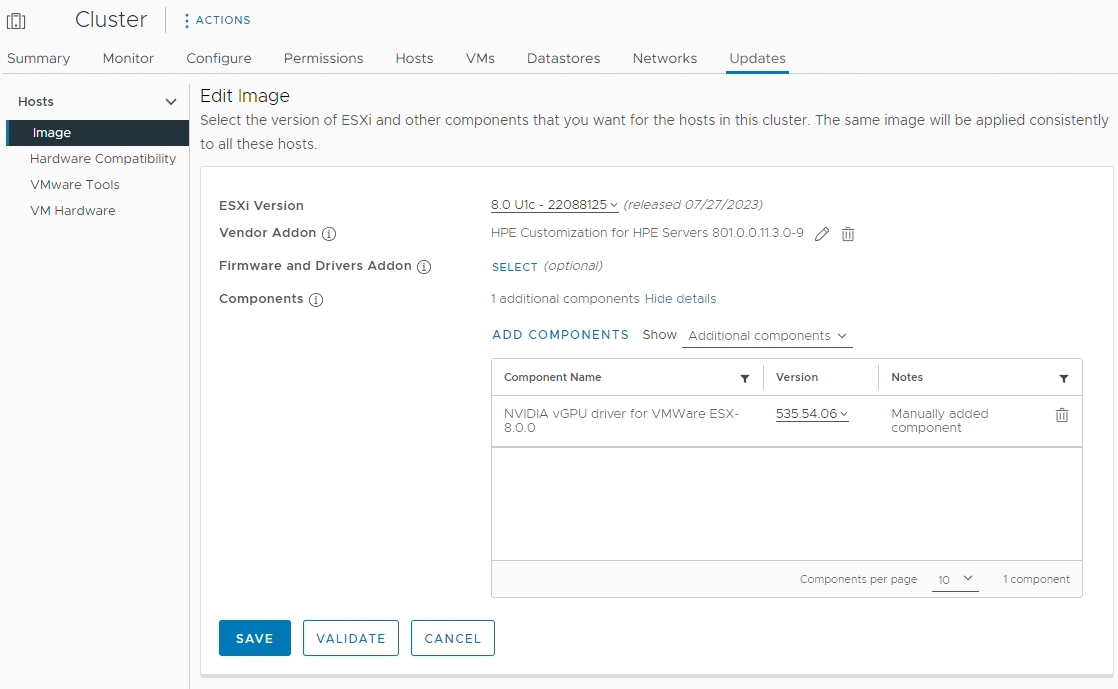
Once LCM has a changed to sync with the updated repos, the driver is then made available to be deployed. You can then deploy using baselines or host images.
LCM Image Update with NVIDIA vGPU Driver from NVIDIA GPU Manager
In the example above, I added the vGPU 16 (535.54.06) host driver to my clusters update image, which I will then remediate and deploy to all the hosts in that cluster. The vGPU driver was made available from the download using GPU Manager.
In this NVIDIA vGPU Troubleshooting Guide, I’ll help show you how to troubleshoot NVIDIA vGPU issues on VMware platforms, including VMware Horizon and VMware Tanzu. This guide applies to the full vGPU platform, so it’s relevant for VDI, AI, ML, and Kubernetes workloads, as well other virtualization platforms.
This guide will provide common troubleshooting methods, along with common issues and problems associated with NVIDIA vGPU as well as their fixes.
Please note, there are numerous other additional methods available to troubleshoot your NVIDIA vGPU deployment, including 3rd party tools. This is a general document provided as a means to get started learning how to troubleshoot vGPU.
NVIDIA vGPU
NVIDIA vGPU is a technology platform that includes a product line of GPUs that provide virtualized GPUs (vGPU) for Virtualization environments. Using a vGPU, you can essentially “slice” up a physical GPU and distribute Virtual GPUs to a number of Virtual Machines and/or Kubernetes containers.
NVIDIA vGPU Installed in VMware ESXi Host
These virtual machines and containers can then use these vGPU’s to provide accelerated workloads including VDI (Virtual Desktop Infrastructure), AI (Artificial Intelligence), and ML (Machine Learning).
While the solution works beautifully, when deployed incorrectly or if the solution isn’t maintained, issues can occur requiring troubleshooting and remediation.
The NVIDIA vGPU driver comes with a utility called the “NVIDIA System Management Interface”. This CLI program allows you to monitor, manage, and query your NVIDIA vGPU (including non-vGPU GPUs).
NVIDIA vGPU “nvidia-smi” command
Simply running the command with no switches or flags, allow you to query and pull basic information on your vGPU, or multiple vGPUs.
For a list of available switches, you can run: “nvidia-smi -h”.
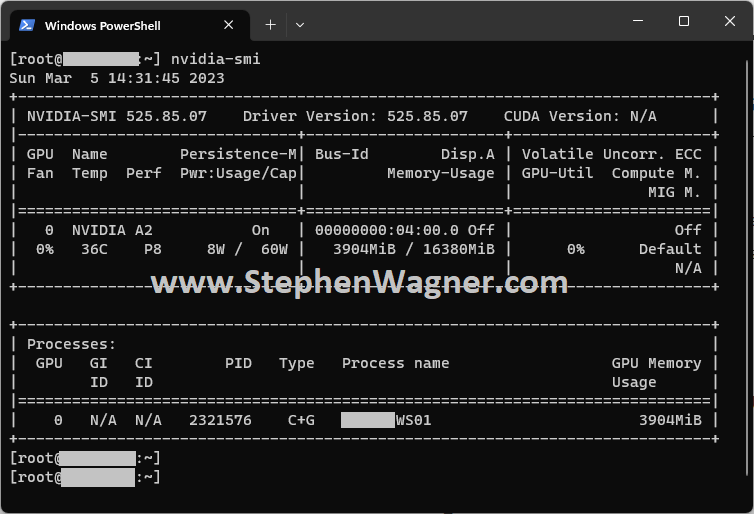
Running “nvidia-smi” on the ESXi Host
To use “nvidia-smi” on your VMware ESXi host, you’ll need to SSH in and/or enable console access.
When you launch “nvidia-smi” on the ESXi host, you’ll see information on the physical GPU, as well as the VM instances that are consuming a virtual GPU (vGPU). This usage will also provide information like fan speeds, temperatures, power usage and GPU utilization.
[root@ESXi-Host:~] nvidia-smi
Sat Mar 4 21:26:05 2023
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 525.85.07 Driver Version: 525.85.07 CUDA Version: N/A |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|===============================+======================+======================|
| 0 NVIDIA A2 On | 00000000:04:00.0 Off | Off |
| 0% 36C P8 8W / 60W | 7808MiB / 16380MiB | 0% Default |
| | | N/A |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=============================================================================|
| 0 N/A N/A 2108966 C+G VM-WS02 3904MiB |
| 0 N/A N/A 2108989 C+G VM-WS01 3904MiB |
+-----------------------------------------------------------------------------+
This will aid with troubleshooting potential issues specific to the host or the VM. The following pieces of information are helpful:
Driver Version
GPU Fan and Temperature Information
Power Usage
GPU Utilization (GPU-Util)
ECC Information and Error Count
Virtual Machine VMs assigned a vGPU
vGPU Type (C+G means Compute and Graphics)
Additionally, instead of running once, you can issue “nvidia-smi -l x” replacing “x” with the number of seconds you’d like it to auto-loop and refresh.
Example:
nvidia-smi -l 3
The above would refresh and loop “nvidia-smi” every 3 seconds.
For vGPU specific information from the ESXi host, you can run:
nvidia-smi vgpu
root@ESXi-Host:~] nvidia-smi vgpu
Mon Mar 6 11:47:44 2023
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 525.85.07 Driver Version: 525.85.07 |
|---------------------------------+------------------------------+------------+
| GPU Name | Bus-Id | GPU-Util |
| vGPU ID Name | VM ID VM Name | vGPU-Util |
|=================================+==============================+============|
| 0 NVIDIA A2 | 00000000:04:00.0 | 0% |
| 3251713382 NVIDIA A2-4Q | 2321577 VMWS01 | 0% |
+---------------------------------+------------------------------+------------+
This command shows information on the vGPU instances currently provisioned.
There are also a number of switches you can throw at this to get even more information on vGPU including scheduling, vGPU types, accounting, and more. Run the following command to view the switches:
nvidia-smi vgpu -h
Another common switch I use on the ESXi host with vGPU for troubleshooting is: “nvidia-smi -q”, which provides lots of information on the physical GPU in the host:
[root@ESXi-HOST:~] nvidia-smi -q
==============NVSMI LOG==============
Timestamp : Sat Mar 4 21:26:18 2023
Driver Version : 525.85.07
CUDA Version : Not Found
vGPU Driver Capability
Heterogenous Multi-vGPU : Supported
Attached GPUs : 1
GPU 00000000:04:00.0
Product Name : NVIDIA A2
Product Brand : NVIDIA
Product Architecture : Ampere
Display Mode : Enabled
Display Active : Disabled
Persistence Mode : Enabled
vGPU Device Capability
Fractional Multi-vGPU : Not Supported
Heterogeneous Time-Slice Profiles : Supported
Heterogeneous Time-Slice Sizes : Not Supported
MIG Mode
Current : N/A
Pending : N/A
Accounting Mode : Enabled
Accounting Mode Buffer Size : 4000
Driver Model
Current : N/A
Pending : N/A
Serial Number : XXXN0TY0SERIALZXXX
GPU UUID : GPU-de23234-3450-6456-e12d-bfekgje82743a
Minor Number : 0
VBIOS Version : 94.07.5B.00.92
MultiGPU Board : No
Board ID : 0x400
Board Part Number : XXX-XXXXX-XXXX-XXX
GPU Part Number : XXXX-XXX-XX
Module ID : 1
Inforom Version
Image Version : G179.0220.00.01
OEM Object : 2.0
ECC Object : 6.16
Power Management Object : N/A
GPU Operation Mode
Current : N/A
Pending : N/A
GSP Firmware Version : N/A
GPU Virtualization Mode
Virtualization Mode : Host VGPU
Host VGPU Mode : SR-IOV
IBMNPU
Relaxed Ordering Mode : N/A
PCI
Bus : 0x04
Device : 0x00
Domain : 0x0000
Device Id : 0x25B610DE
Bus Id : 00000000:04:00.0
Sub System Id : 0x157E10DE
GPU Link Info
PCIe Generation
Max : 3
Current : 1
Device Current : 1
Device Max : 4
Host Max : N/A
Link Width
Max : 16x
Current : 8x
Bridge Chip
Type : N/A
Firmware : N/A
Replays Since Reset : 0
Replay Number Rollovers : 0
Tx Throughput : 0 KB/s
Rx Throughput : 0 KB/s
Atomic Caps Inbound : N/A
Atomic Caps Outbound : N/A
Fan Speed : 0 %
Performance State : P8
Clocks Throttle Reasons
Idle : Active
Applications Clocks Setting : Not Active
SW Power Cap : Not Active
HW Slowdown : Not Active
HW Thermal Slowdown : Not Active
HW Power Brake Slowdown : Not Active
Sync Boost : Not Active
SW Thermal Slowdown : Not Active
Display Clock Setting : Not Active
FB Memory Usage
Total : 16380 MiB
Reserved : 264 MiB
Used : 7808 MiB
Free : 8306 MiB
BAR1 Memory Usage
Total : 16384 MiB
Used : 1 MiB
Free : 16383 MiB
Compute Mode : Default
Utilization
Gpu : 0 %
Memory : 0 %
Encoder : 0 %
Decoder : 0 %
Encoder Stats
Active Sessions : 0
Average FPS : 0
Average Latency : 0
FBC Stats
Active Sessions : 0
Average FPS : 0
Average Latency : 0
Ecc Mode
Current : Disabled
Pending : Disabled
ECC Errors
Volatile
SRAM Correctable : N/A
SRAM Uncorrectable : N/A
DRAM Correctable : N/A
DRAM Uncorrectable : N/A
Aggregate
SRAM Correctable : N/A
SRAM Uncorrectable : N/A
DRAM Correctable : N/A
DRAM Uncorrectable : N/A
Retired Pages
Single Bit ECC : N/A
Double Bit ECC : N/A
Pending Page Blacklist : N/A
Remapped Rows
Correctable Error : 0
Uncorrectable Error : 0
Pending : No
Remapping Failure Occurred : No
Bank Remap Availability Histogram
Max : 64 bank(s)
High : 0 bank(s)
Partial : 0 bank(s)
Low : 0 bank(s)
None : 0 bank(s)
Temperature
GPU Current Temp : 37 C
GPU T.Limit Temp : N/A
GPU Shutdown Temp : 96 C
GPU Slowdown Temp : 93 C
GPU Max Operating Temp : 86 C
GPU Target Temperature : N/A
Memory Current Temp : N/A
Memory Max Operating Temp : N/A
Power Readings
Power Management : Supported
Power Draw : 8.82 W
Power Limit : 60.00 W
Default Power Limit : 60.00 W
Enforced Power Limit : 60.00 W
Min Power Limit : 35.00 W
Max Power Limit : 60.00 W
Clocks
Graphics : 210 MHz
SM : 210 MHz
Memory : 405 MHz
Video : 795 MHz
Applications Clocks
Graphics : 1770 MHz
Memory : 6251 MHz
Default Applications Clocks
Graphics : 1770 MHz
Memory : 6251 MHz
Deferred Clocks
Memory : N/A
Max Clocks
Graphics : 1770 MHz
SM : 1770 MHz
Memory : 6251 MHz
Video : 1650 MHz
Max Customer Boost Clocks
Graphics : 1770 MHz
Clock Policy
Auto Boost : N/A
Auto Boost Default : N/A
Voltage
Graphics : 650.000 mV
Fabric
State : N/A
Status : N/A
Processes
GPU instance ID : N/A
Compute instance ID : N/A
Process ID : 2108966
Type : C+G
Name : VM-WS02
Used GPU Memory : 3904 MiB
GPU instance ID : N/A
Compute instance ID : N/A
Process ID : 2108989
Type : C+G
Name : VM-WS01
Used GPU Memory : 3904 MiB
As you can see, you can pull quite a bit of information in detail from the vGPU, as well as the VM processes.
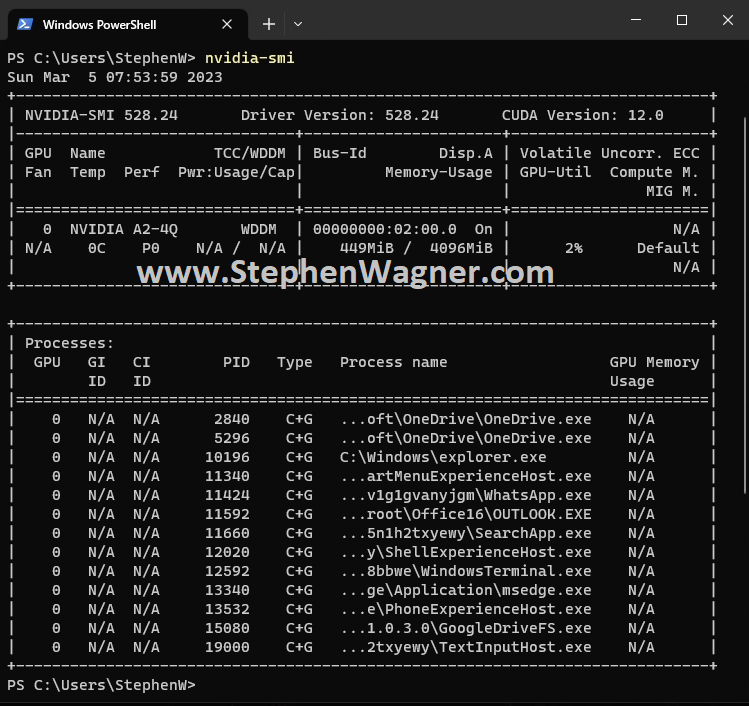
Running “nvidia-smi” on the VM Guest
You can also run “nvidia-smi” inside of the guest VM, which will provide you information on the vGPU instance that is being provided to that specific VM, along with information on the guest VM’s processes that are utilizing the GPU.
“nvidia-smi” Running on Guest VM
This is helpful for providing information on the guest VM’s usage of the vGPU instance, as well as processes that require GPU usage.
Virtual Machine log files
Each Virtual Machine has a “vmware.log” file inside of the VM’s folder on the datastore.
To identify logging events pertaining to NVIDIA vGPU, you can search for the “vmiop” string inside of the vmware.log file.
The above will read out any lines inside of the log that have the “vmiop” string inside of them. The “-i” flag instructs grep to ignore case sensitivity.
This logs provide initialization information, licensing information, as well as XID error codes and faults.
ESXi Host log files
Additionally, since the ESXi host is running the vGPU Host Driver (vGPU Manager), it also has logs that pertain and assist with vGPU troubleshooting.
Some commands you can run are:
cat /var/log/vmkernel.log | grep -i vmiop
cat /var/log/vmkernel.log | grep -i nvrm
cat /var/log/vmkernel.log | grep -i nvidia
The above commands will pull NVIDIA vGPU related log items from the ESXi log files.
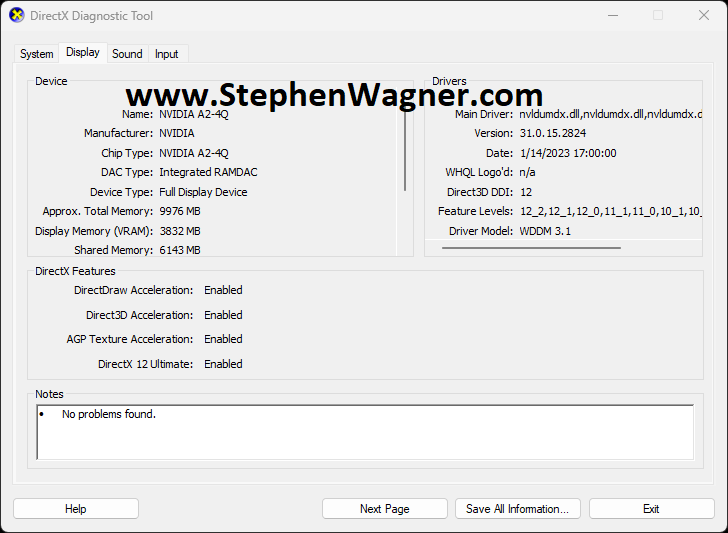
Using “dxdiag” in the guest VM
Microsoft has a tool called “dxdiag” which provides diagnostic infromation for testing and troubleshooting video (and sound) with DirectX.
I find this tool very handy for quickly verifying
NVIDIA vGPU with Microsoft DirectX “dxdiag” tool
As you can see:
DirectDraw Acceleration: Enabled
Direct3D Acceleration: Enabled
AGP Texture Acceleration: Enabled
DirectX 12 Ultimate: Enabled
The above show that hardware acceleration is fully functioning with DirectX. This is a indicator that things are generally working as expected. If you have a vGPU and one of the first three is showing as disabled, then you have a problem that requires troubleshooting. Additionally, if you do not see your vGPU card, then you have a problem that requires troubleshooting.
Please Note: You may not see “DirectX 12 Ultimate” as this is related to licensing.
Using the “VMware Horizon Performance Monitor”
The VMware Horizon Performance Monitor, is a great tool that can be installed by the VMware Horizon Agent, that allows you to pull information (stats, connection information, etc) for the session. Please note that this is not installed by default, and must be selected when running the Horizon Agent installer.
When it comes to troubleshooting vGPU, it’s handy to use this too to confirm you’re getting H.264 or H.265/HEVC offload from the vGPU instance, and also get information on how many FPS (Frames Per Second) you’re getting from the session.
VMware Horizon Performance Tracker with NVIDIA vGPU
Once opening, you’ll change the view above using the specified selector, and you can see what the “Encoder Name” is being used to encode the session.
Examples of GPU Offload “Encoder Name” types:
NVIDIA NvEnc HEVC 4:2:0 – This is using the vGPU offload using HEVC
NVIDIA NvEnc HEVC 4:4:4 – This is using the vGPU offload using HEVC high color accuracy
NVIDIA NvEnc H264 4:2:0 – This is using the vGPU offload using H.264
NVIDIA NvEnc H264 4:4:4 – This is using the vGPU offload using H.264 high color accuracy
Examples of Software (CPU) Session “Encoder Name” types:
BlastCodec – New VMware Horizon “Blast Codec”
h264 4:2:0 – Software CPU encoded h.264
If you’re seeing “NVIDIA NvEnc” in the encoder name, then the encoding is being offloaded to the GPU resulting in optimum performance. If you don’t see it, it’s most likely using the CPU for encoding, which is not optimal if you have a vGPU, and requires further troubleshooting.
NVIDIA vGPU Known Issues
Depending on the version of vGPU that you are running, there can be “known issues”.
When viewing the NVIDIA vGPU Documentation, you can view known issues, and fixes that NVIDIA may provide. Please make sure to reference the documentation specific to the version you’re running and/or the version that fixes the issues you’re experiencing.
vGPU Common Problems
There are a number of common problems that I come across when I’m contacted to assist with vGPU deployments.
Please see below for some of the most common issues I experience, along with their applicable fix/workaround.
XID Error Codes
When viewing your Virtual Machine VM or ESXi log file, and experiencing an XID error or XID fault, you can usually look up the error codes.
The table on this page allows you to lookup the XID code, find the cause, and also provides information if the issue is realted to “HW Error” (Hardware Error), “Driver Error”, “User App Error”, “System Memory Corruption”, “Bus Error”, “Thermal Issue”, or “FB Corruption”.
One can see XID code 45, as well as XID code 43, which after looking up on NVIDIA’s document, states:
XID 43 – GPU stopped processing
Possible Cause: Driver Error
Possible Cause: User App Error
XID 45 – Preemptive cleanup, due to previous errors — Most likely to see when running multiple cuda applications and hitting a DBE
Possible Cause: Driver Error
In the situation above, one can deduce that the issue is either Driver Error, Application Error, or a combination of both. In this specific case, you could try changing drivers to troubleshoot.
vGPU Licensing
You may experience issues in your vGPU deployment due to licensing issues. Depending on how you have you environment configured, you may be running in an unlicensed mode and not be aware.
In the event that the vGPU driver cannot obtain a valid license, it will run for 20 minutes with full capabilities. After that the performance and functionality will start to degrade. After 24 hours it will degrade even further.
Some symptoms of issues experienced when unlicensed:
Users experiencing laggy VDI sessions
Performance issues
Frames per Second (FPS) limited to 15 fps or 3 fps
Applications using OpenCL, CUDA, or other accelerated APIs fail
Additionally, some error messages and event logs may occur:
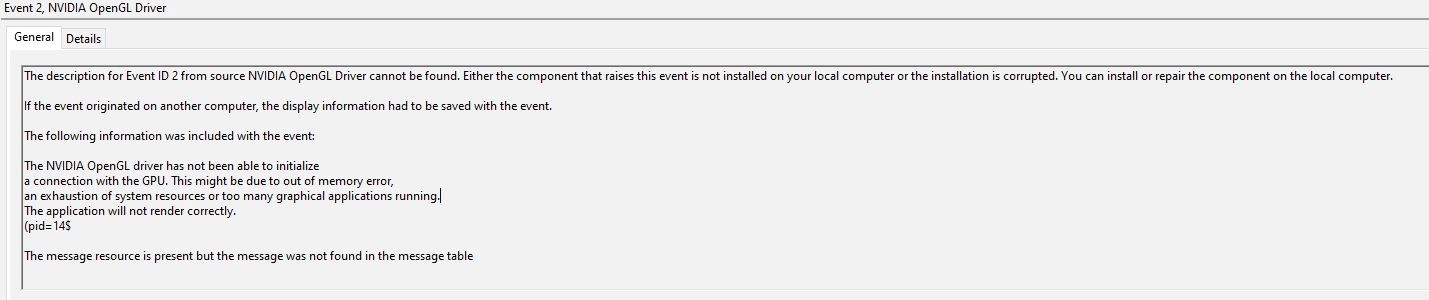
Event ID 2, “NVIDIA OpenGL Driver” – “The NVIDIA OpenGL driver has not been able to initialize a connection with the GPU.”
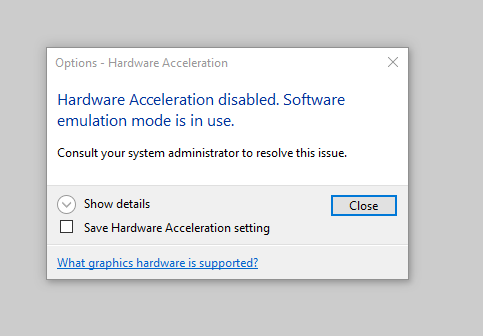
AutoCAD/Revit – “Hardware Acceleration is disabled. Software emulation mode is in use.”
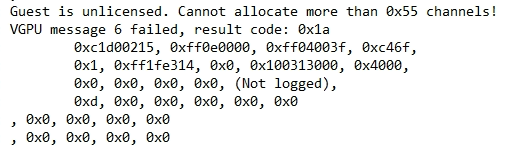
“Guest is unlicensed”
Please see below for screenshots of said errors:
vGPU Guest Is UnlicensedNVIDIA OpenGL Driver Not FoundAutoCAD Hardware Acceleration Disabled
Additonally, when looking at the Virtual Machine VM vmware.log (inside of the VM’s folder on the ESXi datastore), you may see:
Guest is unlicensed. Cannot allocate more than 0x55 channels!
VGPU message 6 failed, result code: 0x1a
If this occurs, you’ll need to troubleshoot your vGPU licensing and resolve any issues occurring.
vGPU Type (vGPU Profile) mismatch
When using the default (“time-sliced”) vGPU deployment method, only a single vGPU type can be used on virtual machines or containers per physical GPU. Essentially all VMs or containers utilizing the physical GPU must use the same vGPU type.
If the physical GPU card has multiple GPUs (GPU chips), then a different type can be used on each physical GPU chip on the same card. 2 x GPUs on a single card = 2 different vGPU types.
Additionally, if you have multiple cards inside of a single host, the number of vGPU types you can deployed is based off the total number of GPUs across the total number of cards in your host.
If you configure multiple vGPU types and cannot support it, you will have issues starting VMs, as shown below:
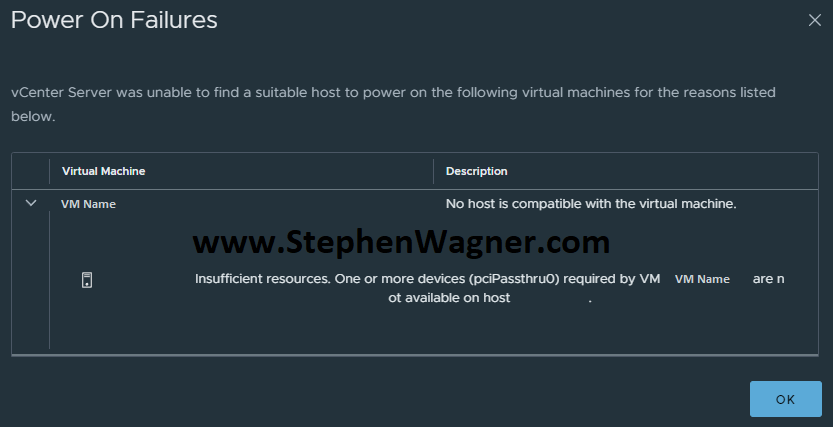
Cannot power on VM with vGPU: Power on Failure, Insuffiecient resources
The error reads as follows:
Power On Failures
vCenter Server was unable to find a suitable host to power on the following virtual machines for the reasons listed below.
Insufficient resources. One or more devices (pciPassthru0) required by VM VDIWS01 are not available on host ESXi-Host.
Additionally, if provisioning via VMware Horizon, you may see: “NVIDIA GRID vGPU Support has detected a mismatch with the supported vGPUs”
Note: If you are using MIG (Multi Instance GPU), this does not apply as different MIG types can be applied to VMs from the same card/GPU.
vGPU or Passthrough with 16GB+ of Video RAM Memory
When attaching a vGPU to a VM, or passing through a GPU to a VM, with 16GB or more of Video RAM (Framebuffer memory), you may run in to a situation where the VM will not boot.
This is because the VM cannot map that large of memory space to be accesible for use.
Your users may report issues where their VDI guest VM freezes for a period of time during use. This could be caused due to VMware vMotion moving the virtual machine from one VMware ESXi host to another.
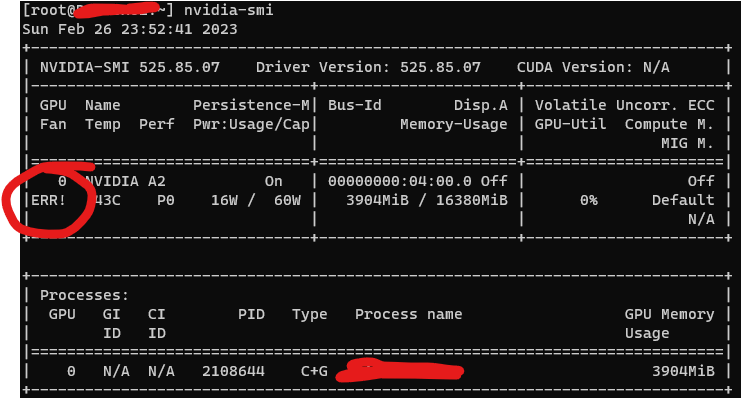
When experiencing issues, you may notice that “nvidia-smi” throws “ERR!” in the view. See the example below:
NVIDIA vGPU “nvidia-smi” reporting “ERR!”
This is an indicator that you’re in a fault or error state, and would recommend checking the ESXi Host log files, and the Virtual Machine log files for XID codes to identify the problem.
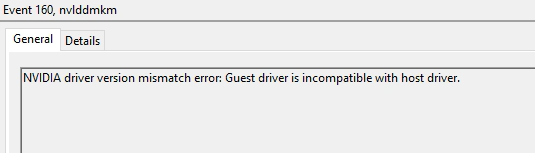
vGPU Driver Mismatch
When vGPU is deployed, drivers are installed on the VMware ESXi host (vGPU Manager Driver), as well as the guest VM virtual machine (guest VM driver).
NVIDIA vGPU Driver Mismatch
These two drivers must be compatible with each other. As per NVIDIA’s Documentation, see below for compatibility:
NVIDIA vGPU Manager with guest VM drivers from the same release
NVIDIA vGPU Manager with guest VM drivers from different releases within the same major release branch
NVIDIA vGPU Manager from a later major release branch with guest VM drivers from the previous branch
Additionally, if you’re using the LTS (Long Term Support Branch), the additional compatibility note applies.
NVIDIA vGPU Manager from a later long-term support branch with guest VM drivers from the previous long-term support branch
If you have a vGPU driver mismatch, you’ll likely see Event ID 160 from “nvlddmkm” reporting:
NVIDIA driver version mismatch error: Guest driver is incompatible with host drive.
To resolve this, you’ll need to change drivers on the ESXi host and/or Guest VM to a supported combination.
Upgrading NVIDIA vGPU
When upgrading NVIDIA vGPU drivers on the host, you may experience issues or errors stating that the NVIDIA vGPU modules or services are loaded and in use, stopping your ability to upgrade.
Normally an upgrade would be preformed by placing the host in maintenance mode and running:
However, this fails due to modules that are loaded and in use by the NVIDIA vGPU Manager Services.
Before attempting to upgrade (or uninstall and re-install), place the host in maintenance mode and run the following command:
/etc/init.d/nvdGpuMgmtDaemon stop
This should allow you to proceed with the upgrade and/or re-install.
VMware Horizon Black Screen
If you experiencing a blank or black screen when connecting to a VDI session with an NVIDIA vGPU on VMware Horizon, it may not even be related to the vGPU deployment.
To troubleshoot the VMware Horizon Black Screen, please review my guide on how to troubleshoot a VMware Horizon Blank Screen.
VM High CPU RDY (High CPU Ready)
CPU RDY (CPU Ready) is a state when a VM is ready and waiting to be scheduled on a physical host’s CPU. In more detail, the VM’s vCPUs are ready to be scheduled on the ESXi host’s pCPUs.
In rare cases, I have observed situations where VMs with a vGPU and high CPU RDY times, experience instability. I believe this is due to timing conflicts with the vGPU’s time slicing, and the VM’s CPU waiting to be scheduled.
To check VM CPU RDY, you can use one of the following methods:
Run “esxtop” from the CLI using the console or SSH
View the hosts performance stats on vCenter
Select host, “Monitor”, “Advanced”, “Chart Options”, de-select all, select “Readiness Average %”
When viewing the CPU RDY time in a VDI environment, generally we’d like to see CPU RDY at 3 or lower. Anything higher than 3 may cause latency or user experience issues, or even vGPU issues at higher values.
For your server virtualization environment (non-VDI and no vGPU), CPU Ready times are not as big of a consideration.
vGPU Profiles Missing from VMware Horizon
When using newer GPUs with older versions of VMware Horizon, you may encounter an issue with non-persistent instant clones resulting in a provisioning error.
This is caused by missing vGPU Types or vGPU Profiles, and requires either downloading the latest definitions, or possibly creating your own.
Issues with the VMware Horizon Indirect Display Driver
You may experience vGPU (and GPU) related issues when using certain applications due to the presence of the VMware Horizon Indirect Display Driver in the Virtual Machine. This is due to the application either querying the incorrect Display Adapter (VMware Indirect Display Driver), or due to lack of multi-display adapter support in the application.
The application, when detecting vGPU and/or GPU capabilities, may query the Indirect Display Adapter, instead of the vGPU in the VM. Resulting in failing to detect the vGPU and/or GPU capabilities.
To workaround this issue, uninstall the VMware Horizon Indirect Display Adapter from the Device Manager in the VM. Please note that if you simply disable it, the issue will still occur as the device must be uninstalled from the Device Manager.
Additionally, under normal circumstances you do not want to modify, change, or remove this display adapter. However this is only a workaround if you are experiencing this issue. Subsequent updates of the VMware Horizon agent will re-install this adapter.
If you’re like me, you want to make sure that your environment is as optimized as possible. I recently noticed that my NVIDIA A2 vGPU was reporting the vGPU PCIe Link Speed and Generation that the card was using was below what it was supposed to be running at on my VMware vSphere ESXi host.
I needed to find out if this was being reported incorrectly, if there was an issue, or something else effecting this. In my case, the specific GPU I was using is supposed to support PCIe Gen4, and has a physical connector supporting 4x, my host has PCIe Gen3 slots, so I should at least be getting Gen3 speeds.
NVIDIA A2 vGPU
The Problem
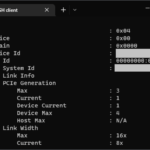
When running the command “nvidia-smi -q”, the GPU was reporting that it was only running at PCIe Gen 1 speeds, as shown below:
GPU Link Info
PCIe Generation
Max : 3
Current : 1
Device Current : 1
Device Max : 4
Host Max : N/A
Link Width
Max : 16x
Current : 8x
Something else worth noting, is that the card states that it supports a 16x interface, when it actually only physical has a 8x connector. I believe they use this chip on another board that has multiple GPUs on a single board that actually supports 16x.
You could say I was quite puzzled. Why would the card only be running at PCIe Generation 1 speeds? I thought it could be any of the scenarios below:
Dynamic mode that alternates when required (possibly for power savings)
Hardware issue
Hardware Limitation (I’m using this in an older server)
Software issues
Configuration issue
Unfortunately, when searching the internet, I couldn’t find many references to this metric, however I did find references from other user’s copy/pastes of “nvidia-smi -q” which had the same values (running PCIe Gen1), even with beefier and more high-end cards.
The Solution
After some more searching, I finally came across an NVIDIA technical document titled “Useful nvidia-smi Queries” that states that the current PCIe Generation Link speed “may be reduced when the GPU is not in use”. This confirms that it’s dynamic and adjusts when needed.
Finally, I decided to give some games a shot in a couple of the VMs, and to my surprise when running a game, the “Device Current” and “Current” PCIe Generation changed to PCIe Gen3 (note that my server isn’t capable of PCIe Gen4, which is the cards maximum), as shown below:
GPU Link Info
PCIe Generation
Max : 3
Current : 3
Device Current : 3
Device Max : 4
Host Max : N/A
Link Width
Max : 16x
Current : 8x
In conclusion, if you notice this in your environment, do not be alarmed as this is completely normal and expected behavior.
This website uses cookies to improve your experience. We'll assume you're ok with this, but you can opt-out if you wish.
Do you accept the use of cookies and accept our privacy policy? AcceptRejectCookie and Privacy Policy
Privacy & Cookies Policy
Privacy Overview
This website uses cookies to improve your experience while you navigate through the website. Out of these cookies, the cookies that are categorized as necessary are stored on your browser as they are essential for the working of basic functionalities of the website. We also use third-party cookies that help us analyze and understand how you use this website. These cookies will be stored in your browser only with your consent. You also have the option to opt-out of these cookies. But opting out of some of these cookies may have an effect on your browsing experience.