
When attempting to log in to your VMware vCenter using the HPE Simplivity Upgrade Manager to perform an upgrade on your Simplivity Infrastructure, the login may fail with Access Denied, Incorrect Credentials, or Incorrect Username and Password.
Despite confirming that the credentials are correct (logging in to the vCenter UI, as well as the vCSA console via SSH), the HPE Simplivity Upgrade Manager will continue to fail on connection.
The Problem
During the login process, the HPE Simplivity Upgrade Manager will not only check the credentials and attempt to logon to the vCenter server, but it will also attempt to pull and validate the SSL certificates (whether trusted or not) on the vCenter server.
During the typical login process, after entering the credentials and clicking “Connect”, the user will be prompted with the SSL certificate information asking to approve the connection. In this specific circumstance the SSL window is not presented.
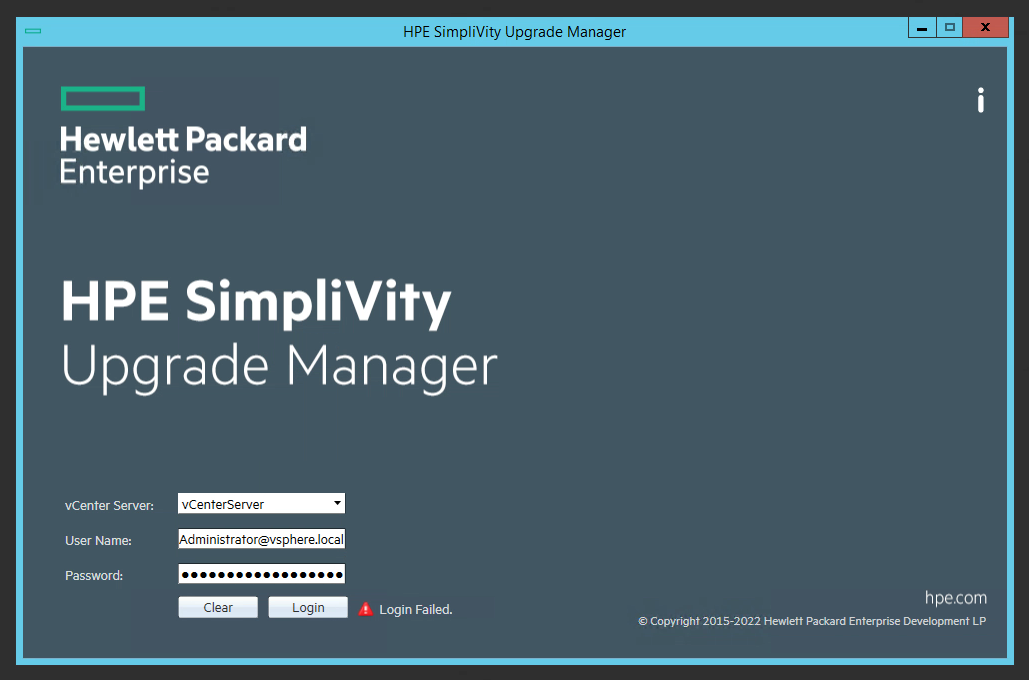
Because of the SSL check not being presented, I thought there may have been a chance with trusting the connection, and possibly HPE Simplivity wasn’t able to show the error specific to the SSL check failing.
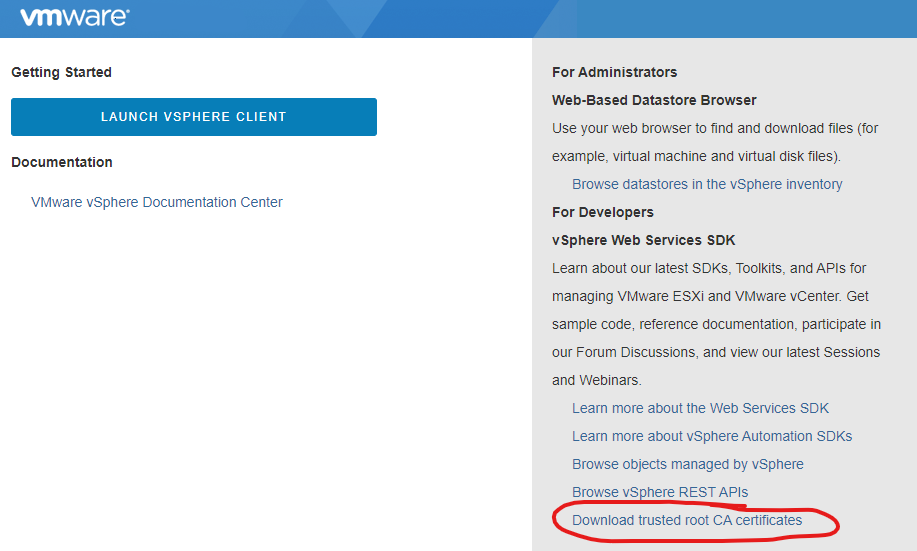
When clicking on this, I was presented with an HTTP 404 error (File not found), meaning the certficiates weren’t present, which I felt may be contributing or causing this problem.
The Solution
After doing a quick search, I was able to find a VMware KB 89325 addressing the issue of being Unable to download Trusted Root Certificates for VCSA because it shows 0kb file.
Logging in to the vCSA appliance, I was able to determine that the appliance was missing the certificate symlink to allow the certificate download by running this command:
ls -ltra /etc/vmware-vpx/docRootInside of the directory listing, there was no symlink for certs, which should point to “/var/lib/vmware-vpx/docRoot/certs”.
I went ahead and created the symlink using the following command:
ln -sfn /var/lib/vmware-vpx/docRoot/certs /etc/vmware-vpx/docRoot/certsWhen using the “ls -ltra /etc/vmware-vpx/docRoot” command from above, I was now able to verify that the symlink existed:
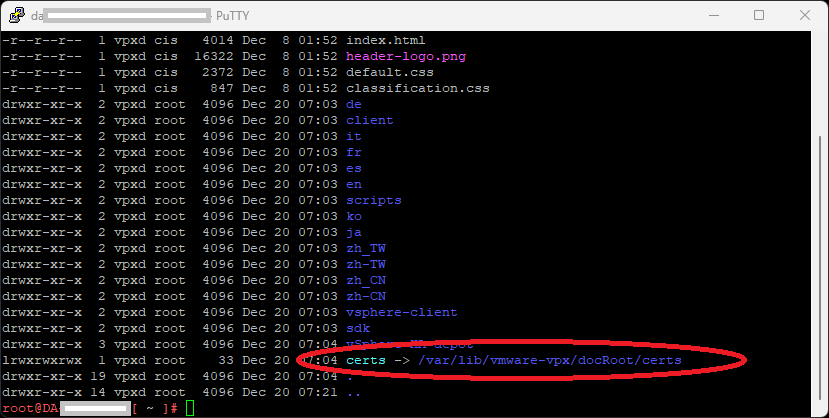
After creating the symlink, I was able to download the Trusted Root CA zip file (you don’t need to do anything with this file as the download was just a test).
I now went back to the Upgrade Manager to attempt to login, and it was successful.
