On VMware vSphere ESXi 6.5, 6.7, and 7.0, a condition exists where one is unable to take a quiesced snapshot. This is an issue that effects quite a few people and numerous forum threads can be found on the internet by those searching for the solution.
This issues can occur both when taking manual snapshots of virtual machines when one chooses “Quiesce guest filesystem”, or when using snapshot based backup applications such as vSphere Data Protection (vSphere vDP), Veeam, or other applications that utilize quiesced snapshots.
The Issue
I experienced this problem on one of my test VMs (Windows Server 2012 R2), however I believe it can occur on newer versions of Windows Server as well, including Windows Server 2016 and Windows Server 2019.
When this issue occurs, the snapshot will fail and the following errors will be present:
An error occurred while taking a snapshot: Failed to quiesce the virtual machine.
An error occurred while saving the snapshot: Failed to quiesce the virtual machine.
Performing standard troubleshooting, I restarted the VM, checked for VSS provider errors, and confirmed that the Windows Services involved with snapshots were in their correct state and configuration. Unfortunately this had no effect, and everything was configured the way it should be.
I also tried to re-install VMWare tools, which had no effect.
PLEASE NOTE: If you experience this issue, you should confirm the services are in their correct state and configuration, as outlined in VMware KB: 1007696. Source: https://kb.vmware.com/s/article/1007696
The Fix
In the days leading up to the failure when things were running properly, I did notice that the quiesced snapshots for that VM were taking a long time process, but were still functioning correctly before the failure.
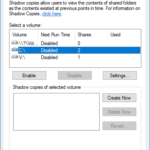
This morning during troubleshooting, I went ahead and deleted all the Windows Volume Shadow Copies (VSS Snapshots) which are internal and inside of the Virtual Machine itself. These are the shadow copies that the Windows guest operating system takes on it’s own filesystem (completely unrelated to VMware).
To my surprise after doing this, not only was I able to create a quiesced snapshot, but the snapshot processed almost instantly (200x faster than previously when it was functioning).
If you’re comfortable deleting all your snapshots, it may also be a good idea to fully disable and then re-enable the VSS Snapshots on the volume to make sure they are completely deleted and reset.
I’m assuming this was causing a high load for the VMware snapshot to process and a timeout was being hit on snapshot creation which caused the issue. While Windows volume shadow copies are unrelated to VMware snapshots, they both utilize the same VSS (Volume Shadow Copy Service) system inside of windows to function and process. One must also keep in mind that the Windows volume shadow copies will of course be part of a VMware snapshot since they are stored inside of the VMDK (the virtual disk) file.
PLEASE NOTE: Deleting your Windows Volume Shadow copies will delete your Windows volume snapshots inside of the virtual machine. You will lose the ability to restore files and folders from previous volume shadow copy snapshots. Be aware of what this means and what you are doing before attempting this fix.